结构化分析与设计方法
结构化设计方法
软件工程 第二部分 第4章,主讲人:李欣
Created: 2023-03-27 Mon 13:36
0.1. 互动课堂
0.2. 签到
0.3. 本次课的目标
- 第二部分:结构化分析与设计方法
- 第4章:结构化设计方法
- 软件设计的概念及原则
- 结构化设计
- 体系结构 设计
- 接口 设计
- 数据 设计
- 过程 设计
- 软件设计规格说明
- 软件设计评审
- 第4章:结构化设计方法
1. 软件设计的概念及原则
1.1. 软件设计的概念
1.1.1. 什么是设计
设计 是一项核心的工程活动。
在20世纪90年代早期, Lotus 1-2-3 的发明人 Mitch Kapor 在 Dr. Dobbs 杂志上发表了 软件设计宣言 ,其中指出:
什么是 设计 ?
设计是你站在两个世界 —
技术世界 和人类的 目标世界 ,
而你尝试将这两个世界 结合 在一起……
1.1.2. 设计良好的建筑与软件
罗马建筑批评家 Vitruvius 提出了这样一个观念:
设计良好的建筑应该展示出 坚固 、 适用 和令人 赏心悦目 。
%%{init: { 'theme': 'neutral', 'fontFamily': 'KaiTi' }}%%
graph LR
S["设计良好的软件"] --> A["坚固"] --> A_["程序应不含任何对其功能有障碍的缺陷"]
S --> B["适用"] --> B_["程序需符合开发的目标"]
S --> C["赏心悦目"] --> C_["使用程序的体验应是愉快的"]
@startuml
skinparam defaultFontName Times New Roman, KaiTi
left to right direction
title 从设计良好的建筑来思考好的软件应具备的属性
node 设计良好的软件
设计良好的软件 -[#red]-> 坚固
设计良好的软件 -[#green]-> 适用
设计良好的软件 -[#blue]-> 赏心悦目
坚固 -[#red]-> 程序应不含任何对其功能有障碍的缺陷
适用 -[#green]-> 程序需符合开发的目标
赏心悦目 -[#blue]-> 使用程序的体验应是愉快的
@enduml

Figure 1: 从设计良好的建筑来思考好的软件应具备的属性
1.2. 软件设计的原则
- 依据什么准则将软件系统 划分 成若干独立的成分?
- 在各个不同的成分内,功能细节和数据结构细节如何 表示 ?
- 用什么标准可对软件设计的技术质量做统一的
衡量 ?
1.2.1. 原则1 分而治之
分而治之 是人们解决 大型复杂问题 时通常采用的策略。
- 将 大型复杂问题 分解为许多容易解决的 小问题 ,则更容易解决。
- 软件的 体系结构设计 、 模块化设计 是分而治之策略的具体表现。
尽管模块分解可以简化要解决的问题,但 模块分解并不是越小越好 。
- 模块数目增加,使得:
- 正面 每个模块 规模 减小,开发单个模块的 成本 减少;
- 负面 模块之间关系的 复杂程度 增加,设计模块间接口所需要的 工作量 增加。
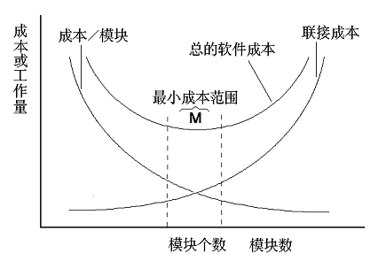
Figure 2: 模块大小、模块数目与成本的关系
1.2.2. 原则2 模块独立性
模块独立性 是指软件系统中 每个模块 只涉及软件要求的具体的 子功能 , 而与软件系统中 其他模块 的 接口 是 简单 的。
若一个模块只具有 单一的功能 且与其他模块没有太多的联系, 我们则称此模块具有 模块独立性 。
- 度量模块独立性的两个准则
- 耦合 是 模块之间 的 相对独立性 (互相连接的紧密程度)的度量。 模块之间的 连接越紧密 , 联系越多 , 耦合性就越高 ,而其模块 独立性就越弱 。
- 内聚 是 模块 功能强度 (一个模块内部各个元素彼此结合的紧密程度)的度量。 一个模块内部各个元素之间的 联系越紧密 ,则它的 内聚性就越高 , 相对地,它与其他模块之间的耦合性就会降低,而模块 独立性就越强 。
- 模块独立性比较强的模块应是怎样的模块?
| 参与人数 | 0 |
|---|---|
| 高度内聚、松散耦合的模块 | 0 |
| 低度内聚、紧密耦合的模块 | 0 |
1.2.3. 原则3 提高抽象层次
抽象 是指 忽视 一个主题中与当前目标 无关 的方面, 以便更充分地 注意 与当前目标 有关 的方面。
当我们进行软件设计时,设计开始时应尽量提高软件的抽象层次, 按 抽象级别 从 高 到 低 进行软件设计。
- 将软件的体系结构按 自顶向下 方式,
对各个层次的 过程细节 和 数据细节 逐层细化,
直到用程序设计语言的语句能够实现为止,
从而最后确立整个系统的体系结构。
这也是常说的 自顶向下、逐步细化 设计过程。
- 在 最高 的抽象层次上,使用问题 所处环境的语言 概括地描述问题的解决方案;
- 在 较低 的抽象层次上,采用更过程化的方法,将 面向问题的术语 和 面向实现的术语 结合起来描述问题的解法;
- 在 最低 的抽象层次上,用某种 程序设计语言 来描述问题的解法。
过程抽象 和 数据抽象 是两种常用的抽象手段。
1.2.4. 原则4 复用性设计
复用 是指同一事物 不做修改 或 稍加修改 就可以 多次重复使用 。
- 将复用的思想用于软件开发,称为 软件复用 。
- 软件的重用部分称为 软构件 。
在构造新的软件系统时不必从零做起, 可以直接使用 已有的 软构件 即可组装(或加以合理修改)成新的系统。
- 复用性设计 有两方面的含义:
- 尽量使用 已有的构件 ,包括 开发环境提供的 及 以往开发类似系统时创建的 ;
- 如果确实需要创建 新的构件 ,则在设计时应该考虑 将来的可重复使用性 。
1.2.5. 原则5 灵活性设计
保证软件 灵活性设计 的关键是 抽象 。
- 面向对象系统中的 类结构 类似金字塔,越接近塔顶, 抽象 程度越高。
- 抽象 的反义词是 具体 。
理想情况下,一个系统的任何 代码 、 逻缉 、 概念 在这个系统中都应该是 唯一 的, 也就是说 不存在重复的代码 。
- 在设计中引入灵活性的方法
- 降低 耦合 并 提高 内聚 (易于提高替换能力)
- 建立 抽象 (创建有多态操作的接口和父类)
- 不要将代码写死( 消除 代码中的 常数 )
- 抛出 异常 (由操作的调用者处理异常)
- 使用 并 创建 可复用代码
2. 结构化设计
2.1. 结构化软件设计的任务
结构化软件设计 的主要任务是要解决 如何做 的问题,
要在
需求分析 的基础上建立各种 设计模型 ,
并通过对设计模型的 分析 和 评估 ,来确定这些模型 是否能够满足需求 。
- 软件设计 是将 用户需求 准确地转化成为最终的 软件产品 的唯一途径, 在 需求 到 构造 之间起到了 桥梁 作用。
在软件设计阶段,往往存在 多种设计方案 , 通常需要在多种设计方案之中进行 决策 和 折中 , 并使用选定的方案进行后续的开发活动。
可从 管理 和 技术 两个不同的角度来认识 设计阶段 及 设计内容 。
- 从不同角度认识软件设计阶段及设计内容
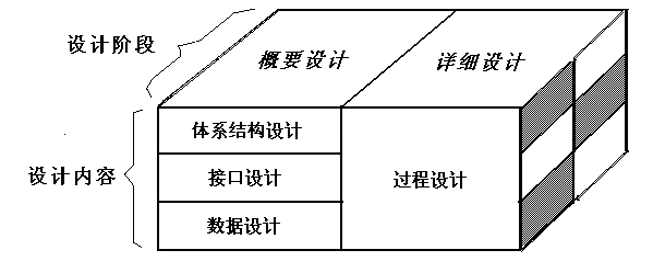
Figure 3: 设计阶段及设计内容
- 体系结构设计 定义软件 模块 及其之间的 关系 ,也称为 模块设计 。
- 接口设计 包括:
- 外部接口设计 (依据分析模型中的 顶层数据流图 )。 外部接口 包括 用户界面 , 目标系统与其他硬件设备、软件系统的外部接口 。
- 内部接口设计 。 内部接口 是指 系统内部各种元素之间的接口 。
- 数据设计 根据需求阶段所建立的 实体–关系图(ER图) 来确定软件涉及的 文件系统 的 结构 及 数据库 的 表结构 。
- 过程设计 是确定软件各个组成部分内的 算法 及 内部数据结构 , 并选定某种表达形式来描述各种算法。
%%{init: { 'theme': 'forest', 'fontFamily': 'Times New Roman, KaiTi' }}%%
flowchart LR
S>"软件设计阶段(工程管理的角度)"]
S ==> A["概要设计阶段"]
S ==> B["详细设计阶段"]
subgraph G1["概要设计阶段任务"]
direction TB
R["软件需求"] --> Q1("概要设计") --> D1["数据结构"]
Q1 --> D2["软件的系统结构"]
end
subgraph G2["详细设计阶段任务"]
direction TB
D["结构表示"] --> Q2("详细设计") --> E1["详细的数据结构"]
Q2 --> E2["算法"]
end
A -.- G1
B -.- G2

Figure 4: 软件设计阶段(工程管理的角度)
%%{init: { 'theme': 'forest', 'fontFamily': 'Times New Roman, KaiTi' }}%%
flowchart LR
B>"软件设计内容(技术的角度)"] ==> BA["结构化设计方法"]
B ==> BB["面向对象设计方法"]
subgraph G1["概要设计阶段"]
BAA["体系结构设计"]
BAB["接口设计"]
BAC["数据设计"]
end
subgraph G2["详细设计阶段"]
BAD["过程设计"]
end
BA --> BAA
BA --> BAB
BA --> BAC
BA --> BAD
BB --> BBA["体系结构设计"]
BB --> BBB["接口设计(人机交互设计)"]
BB --> BBC["数据设计"]
BB --> BBD["类设计"]
BB --> BBE["构件设计"]

Figure 5: 软件设计内容(技术的角度)
2.2. 结构化设计与结构化分析的关系
结构化分析 的结果为 结构化设计 提供了最基本的 输入 信息。
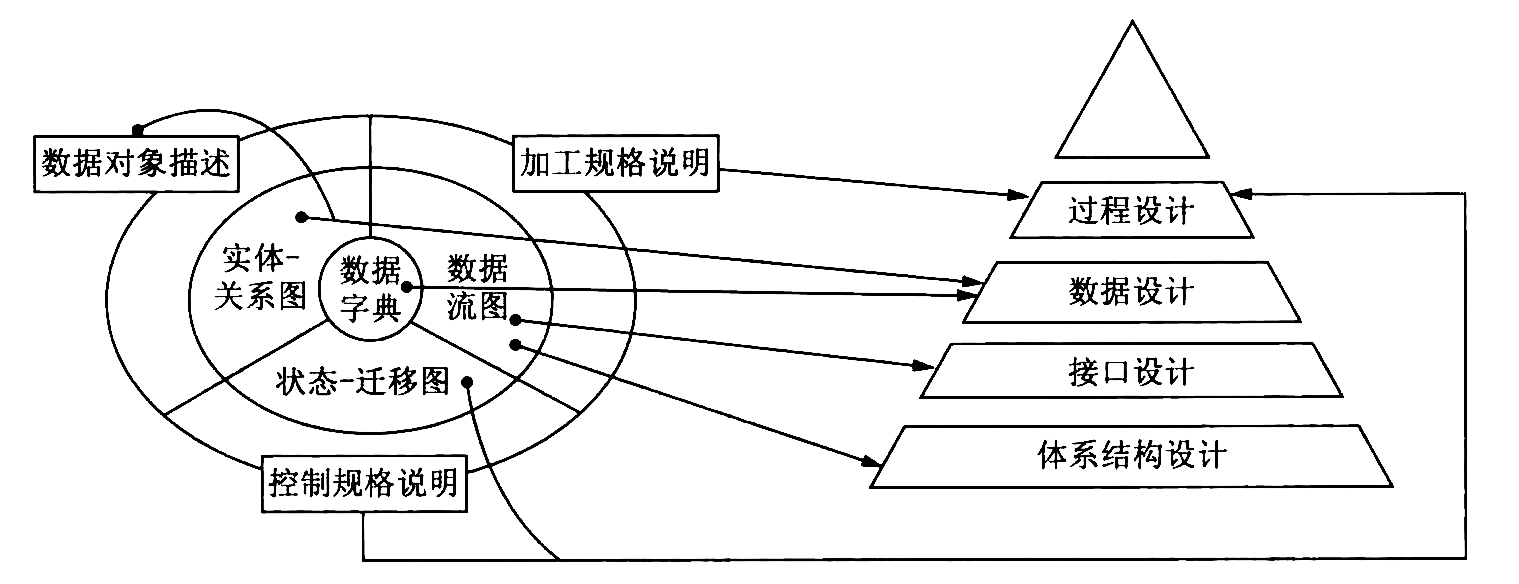
Figure 6: 结构化设计与结构化分析的关系
- 结构化设计方法的实施要点
- 研究 、 分析 和 审查 数据流图 。
- 根据 数据流图 决定问题的类型: 变换型 和 事务型 。 针对两种不同的类型分别进行分析处理。
- 由 数据流图 推导出系统的 初始结构图 。
- 利用一些 启发式原则 来改进系统的 初始结构图 ,直到得到 符合要求 的 结构图 为止。
- 根据分析模型中的 实体关系图 和 数据字典 进行 数据设计 , 包括 数据库设计 或 数据文件的设计 。
- 在上面设计的基础上,并依据分析模型中的 加工规格说明 、 状态转换图 及 控制规格说明 进行 过程设计 。
- 制定 测试计划 。
2.3. 模块结构及表示
- 软件结构包括的两部分
- 一部分为软件的 模块结构 ;
- 另一部分为软件的 数据结构 。
- 软件结构设计所采用的过程
- 一般通过 功能划分过程 来完成 软件结构设计 。该过程
- 从 需求分析 确立的 目标系统 的 模型 出发,将整个问题分割成若干部分;
- 每一部分用 一个 或 几个 软件 模块 加以解决,从而解决整个问题。
- 一般通过 功能划分过程 来完成 软件结构设计 。该过程
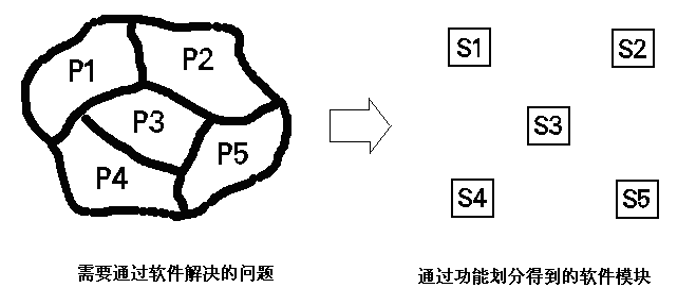
Figure 7: 软件结构的形成
(从软件需求分析到软件设计的过渡)
2.3.1. 模块
一个软件系统通常由很多模块组成, 结构化程序设计中的 函数 和 子程序 都可称为 模块 , 它是 程序语句 按 逻辑关系 建立起来的组合体。
- 模块的表示
- 模块 用 矩形框 表示,并用 模块的名字 标记它;
- 模块的名字 应当能够表明该模块的 功能 ;
- 现成的模块 以 双纵边矩形框 表示。

Figure 8: 模块的表示
- 模块的分解
- 对于 大的模块 ,一般还可以继续 分解 或 划分 为 功能独立 的
较小的模块 。 - 不能再分解的模块称为 原子模块 。
- 对于 大的模块 ,一般还可以继续 分解 或 划分 为 功能独立 的
如果一个软件系统,
- 全部 实际加工 (即 数据计算 或 处理 )都由
原子模块 来完成,- 其他所有 非原子模块 仅仅执行 控制 或 协调 功能,
这样的系统就是 完全因子分解 的系统,完全因子分解的系统被认为是 最好的系统 。 但实际上,这只是我们力图达到的目标,大多数系统做不到完全因子分解。
- 模块的分类(按照在软件系统中的功能)
- 传入模块 取得数据或输入数据 ,经过某些处理,再将其 传送给其他模块 。 传送的数据流A叫做 逻辑输入数据流 。
- 传出模块 输出数据 ,在输出之前可能进行某些处理,数据可能被输出到系统的外部, 也可能会输出到其他模块做进一步的处理,但最终的目标是 输出到系统的外部 。 传送的数据流D叫做 逻辑输出数据流 。
- 变换模块 也叫做加工模块,它从 上级调用模块取得数据 ,进行特定的处理, 转换成其他形式,再将加工结果 返回给调用模块 。 它加工的数据流叫做 变换数据流 ,如将B变换为C。
- 协调模块 本身一般 不对数据进行加工 ,如数据X和Y, 主要功能是通过 调用 、 协调 和 管理 其他模块来完成 特定的功能 , 如结构化程序设计中的主程序。
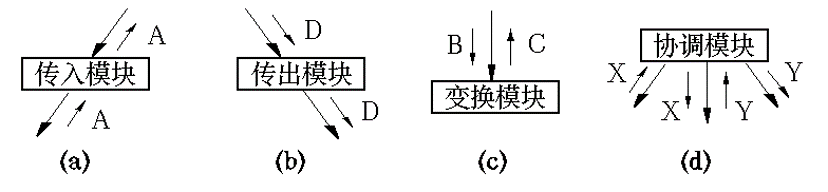
Figure 9: 模块的分类
2.3.2. 模块结构
模块结构 最普通的形式就是 树状结构 和 网状结构 。
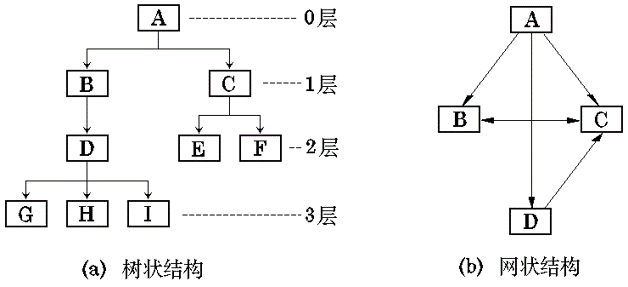
Figure 10: 模块的树状结构和网状结构
- 你认为哪种模块结构比较好?
| 参与人数 | 0 |
|---|---|
| 树状结构 | 0 |
| 网状结构 | 0 |
- 模块结构的比较
- 树状结构
- 只有一个顶层模块,上层模块调用下层模块;
- 同一层模块之间不相互调用。
- 网状结构
- 不存在上级模块和下属模块的关系,无法区分出层次;
- 任何两个模块都是平等的,没有从属关系。
- 任意两个模块间都可以有调用关系。
- 树状结构
- 在软件模式设计时,建议采用 树状结构 , 但往往可能在最底层存在一些 公共模块 (大多数为 数据操作模块 ), 使得实际软件的模块结构 不是 严格意义上的 树状结构 ,这属于正常情况。
- 不加限制的 网状结构 ,由于模块间相互关系的 任意性 , 使得整个结构十分 复杂 ,处理起来势必引起许多麻烦。 这与原来划分模块以便于处理的意图相矛盾。
所以在软件开发的实践中,人们通常采用 树状结构 ,而不采用 网状结构 。
2.3.3. 结构图
结构图(structure chart, SC) 是精确表达 模块结构 的图形表示工具。
它不仅严格地定义了各个模块的 名字 、 功能 和 接口 , 而且还集中地反映了 设计思想 。
- 模块的调用关系和接口
- 在结构图中,两个模块之间用 单向箭头 连接。
- 箭头从 调用模块 指向 被调用模块 ,这表示:
- 调用模块 调用了 被调用模块 ;
- 被调用模块 执行完成之后, 控制 又返回到 调用模块 。
有些结构图中模块间的调用关系将 箭头 简单地画为 连线 , 这时只要调用与被调用模块的 上下位置 保持就是允许的。
- 模块间的信息传递
- 当一个模块调用另一个模块时, 调用模块 把 数据 或 控制信息 传送给 被调用模块 , 以使被调用模块能够运行。
- 而 被调用模块 在执行过程中又把它产生的 数据 或 控制信息 回送给 调用模块 。
- 为了表示在模块之间传递的 数据 或 控制 信息, 在联结模块的箭头旁边给出 短箭头 ,并且
- 用尾端带有 空心圆 的短箭头表示 数据信息 ,
- 用尾端带有 实心圆 的短箭头表示 控制信息 。
- 通常在短箭头附近应注有 信息的名字 。
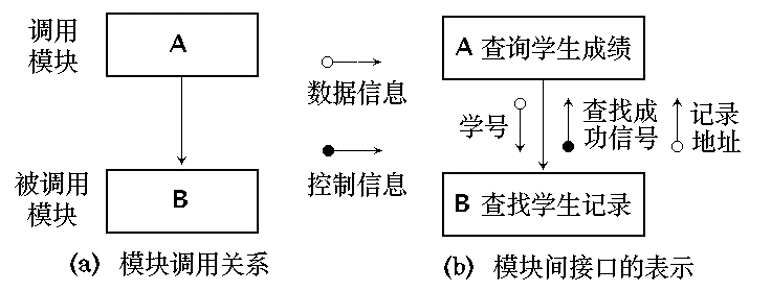
Figure 11: 模块间的调用关系和接口表示
- 两个辅助符号
- 当模块 \(A\) 有条件地 调用另一个模块 \(B\) 时, 在模块 \(A\) 的 箭头尾部 标以一个 菱形 符号;
- 当一个模块 \(A\) 反复地 调用模块 \(C\) 和模块 \(D\) 时, 在调用 箭头尾部 标以一个 弧形 符号。
在结构图中,这种
- 条件调用 所依赖的 条件 和
- 循环调用 所依赖的 循环控制条件
通常都 无需注明 。
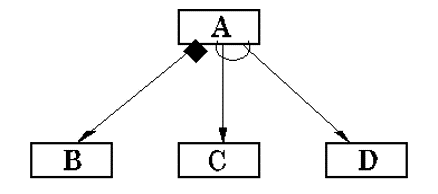
Figure 12: 条件调用和循环调用的表示
- 结构图的形态特征
- 在结构图中, 上级模块 调用 下级模块 ,它们之间存在 主从 关系,即
- 自上而下 是 主宰 关系,
- 自下而上 是 从属 关系。
- 而 同一层的模块 之间并 没有 这种主从关系。
- 在结构图中, 上级模块 调用 下级模块 ,它们之间存在 主从 关系,即
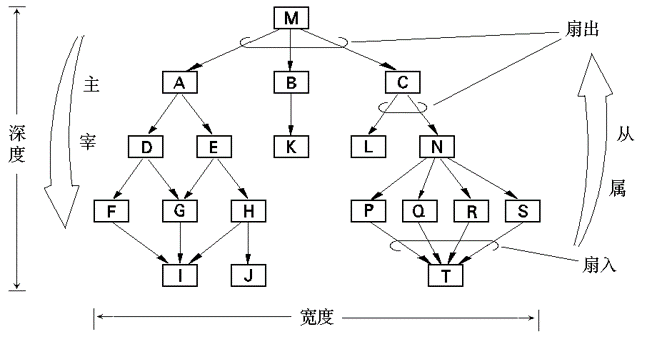
Figure 13: 结构图示例
2.4. 数据结构及表示
- 数据结构 是数据的各个元素之间 逻辑关系 的一种表示。
- 数据结构设计 应确定
- 数据 的 组织 、 存取方式 、 相关程度 ,以及
- 信息 的不同 处理方法 。
- 数据结构的 组织方法 和 复杂程度 可以灵活多样, 但 典型的数据结构 种类是有限的, 它们是构成一些更 复杂结构 的 基本构件块 。
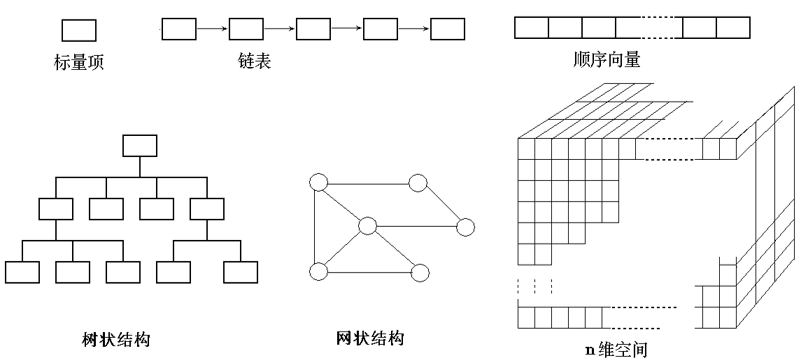
Figure 14: 典型的数据结构
3. 体系结构设计
3.1. 基于数据流方法的设计过程
- 复查并精化数据流图 :对需求分析阶段得出的数据流图认真 复查 ,并在必要时进行 精化 。
- 确定数据流图中数据流的类型 :典型的数据流类型有 变换型数据流 和 事务型数据流 , 数据流类型决定了映射的方法。
- 导出初始的软件结构图 。根据数据流类型, 应用 变换型映射方法 或 事务型映射方法 得到 初始的 软件结构图 。
- 逐级分解 :对软件结构图进行逐级分解,一般需要进行 一级分解 和 二级分解 , 如果需要,也可以进行更多级的分解。
- 精化软件结构 :使用 设计度量 和 启发式规则 对得到的软件结构 进一步精化 。
- 导出接口描述和全局数据结构 :对每一个模块,给出进出该模块的信息,即该模块的 接口描述 。 此外,还需要对所使用的 全局数据结构 给出描述。
基于数据流的设计方法 可以很方便地将 数据流图 中表示的 数据流 映射成
软件结构 。
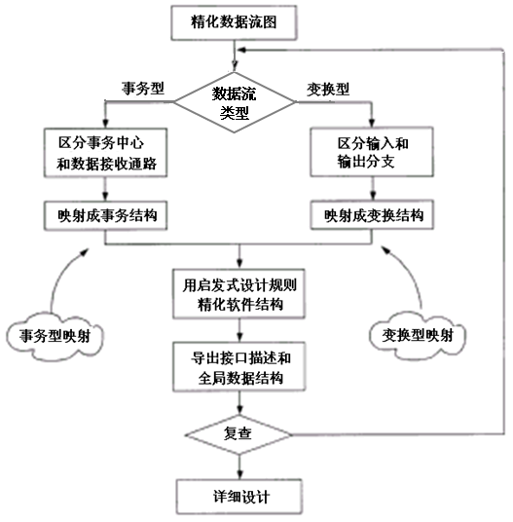
Figure 15: 基于数据流方法的设计过程
3.2. 典型的数据流类型和系统结构
- 典型的数据流类型有 变换型数据流 和 事务型数据流 , 数据流的类型不同,得到的系统结构也不同。
- 通常,一个系统中的所有数据流都可以认为是 变换 流,
- 但是,当遇到有明显事务特性的数据流时,建议采用 事务 型映射方法进行设计。
3.2.1. 变换型数据流与变换型系统结构图
- 变换型数据处理问题工作过程
- 取得数据 : 预处理工作
- 变换数据 : 核心工作
- 给出数据 : 后处理工作

Figure 16: 变换型数据流
- 变换型系统结构图组成部分
- 输入
- 中心变换
- 输出
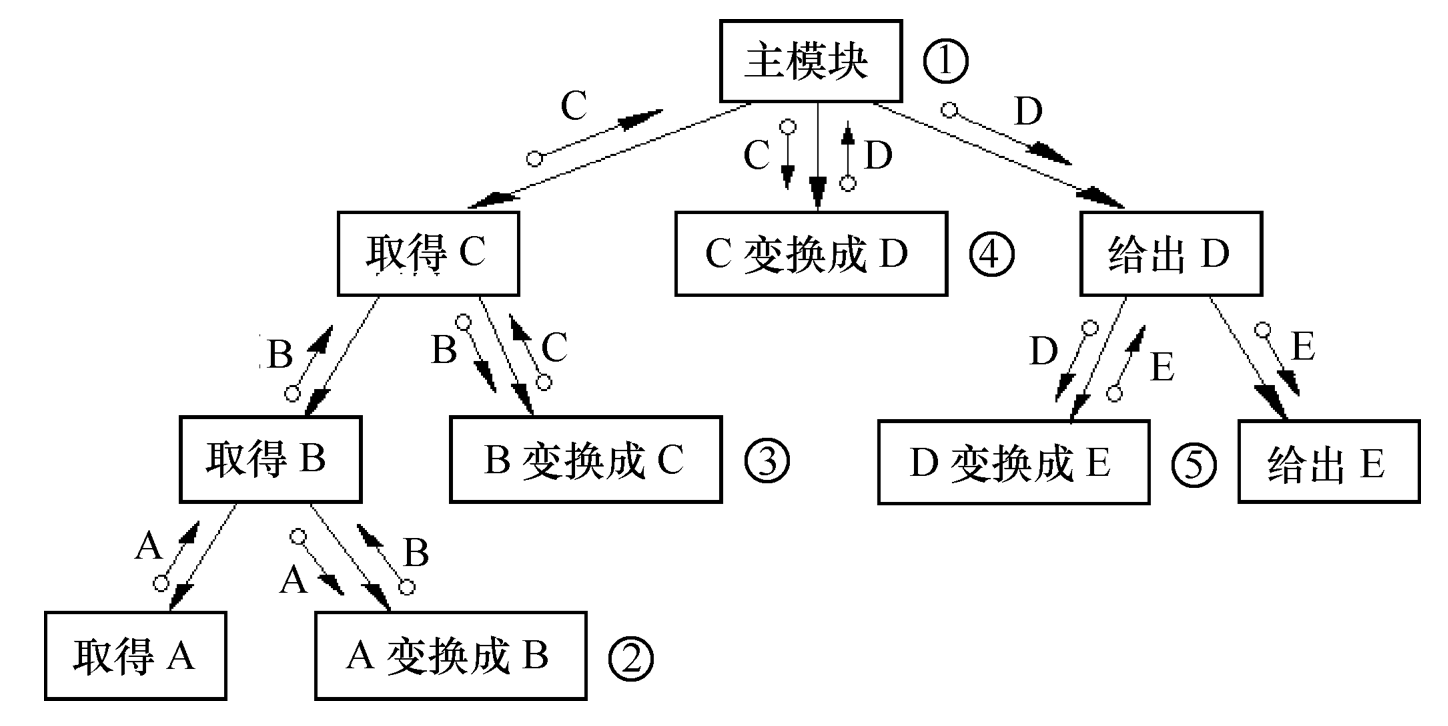
Figure 17: 变换型系统结构图
3.2.2. 事务型数据流与事务型系统结构图
- 事务型数据处理问题工作过程
- 接受一项事务,
- 根据事务处理的特点和性质,选择分派一个适当的处理单元,
- 然后给出结果。
完成选择分派任务的部分叫做 事务处理中心 ,或 分派部件 。
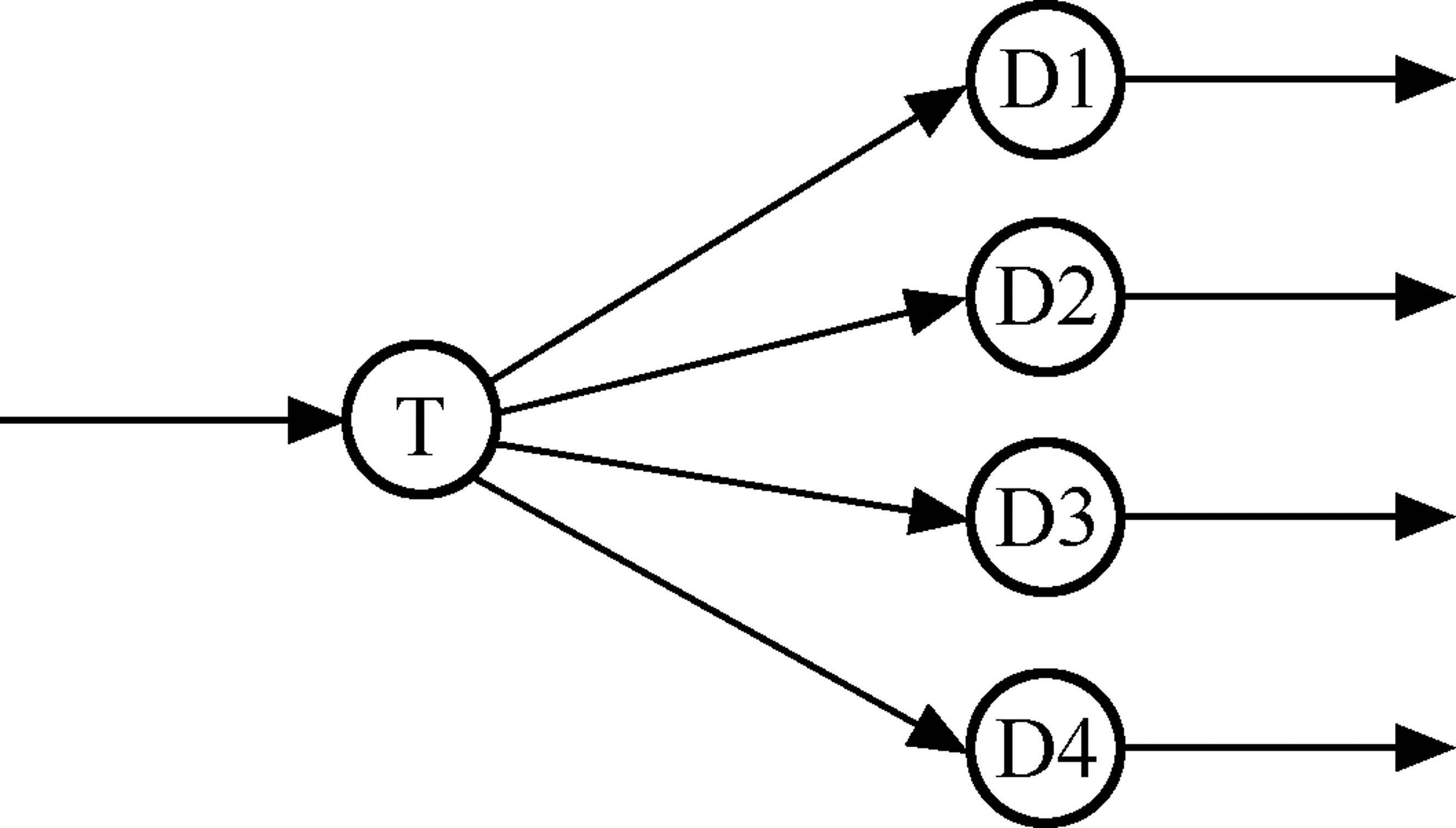
Figure 18: 事务型数据流
事务型数据流图所对应的系统结构图就是 事务型系统结构图 。
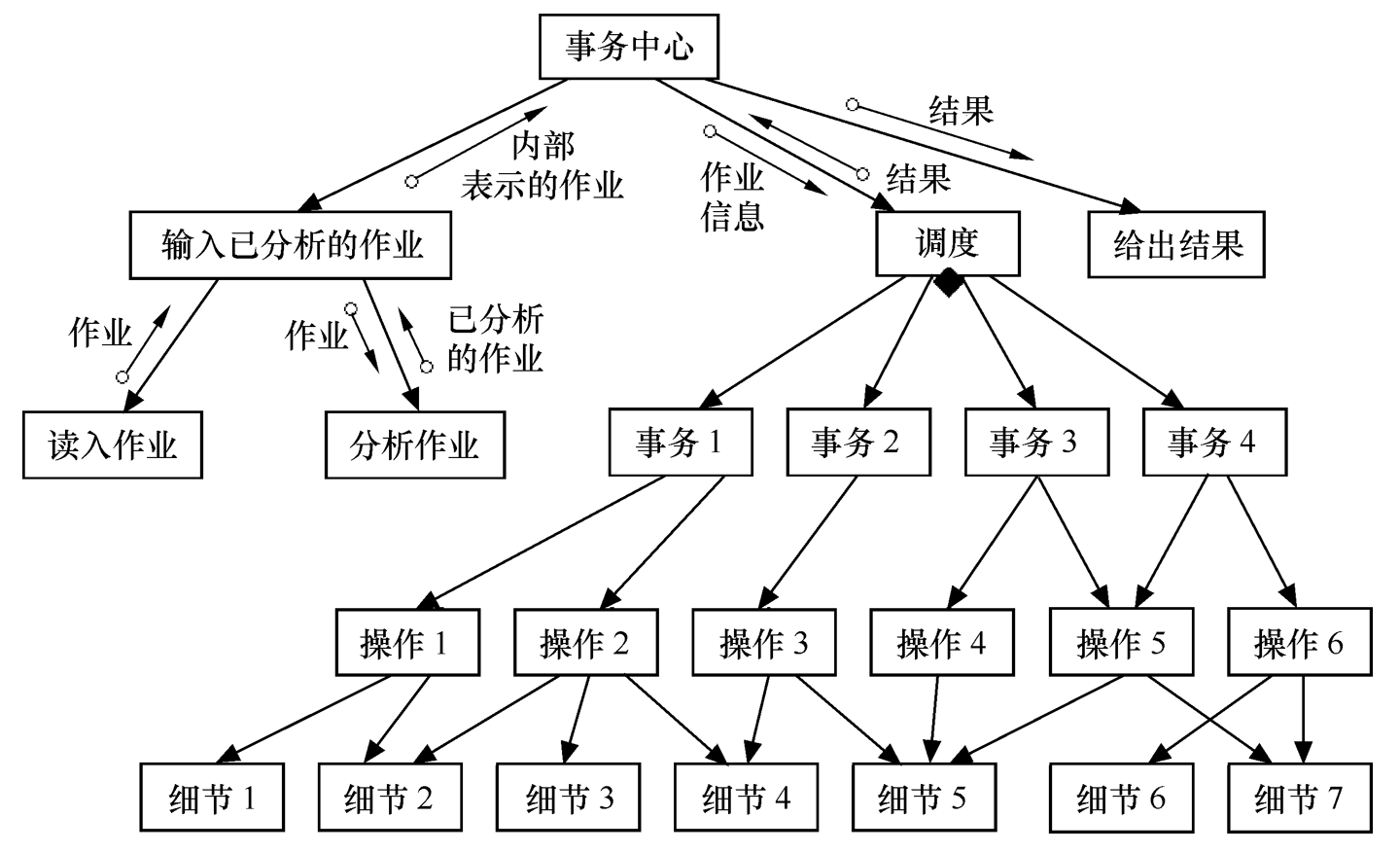
Figure 19: 事务型系统结构图
- 事务型系统结构图的不同形式
- 事务型系统结构图可以有多种不同的形式。例如,有 多层操作层 或
没有操作层 。 - 事务型系统结构图的 简化形式 是把 分析作业 和 调度 都归入 事务中心 模块。
- 事务型系统结构图可以有多种不同的形式。例如,有 多层操作层 或
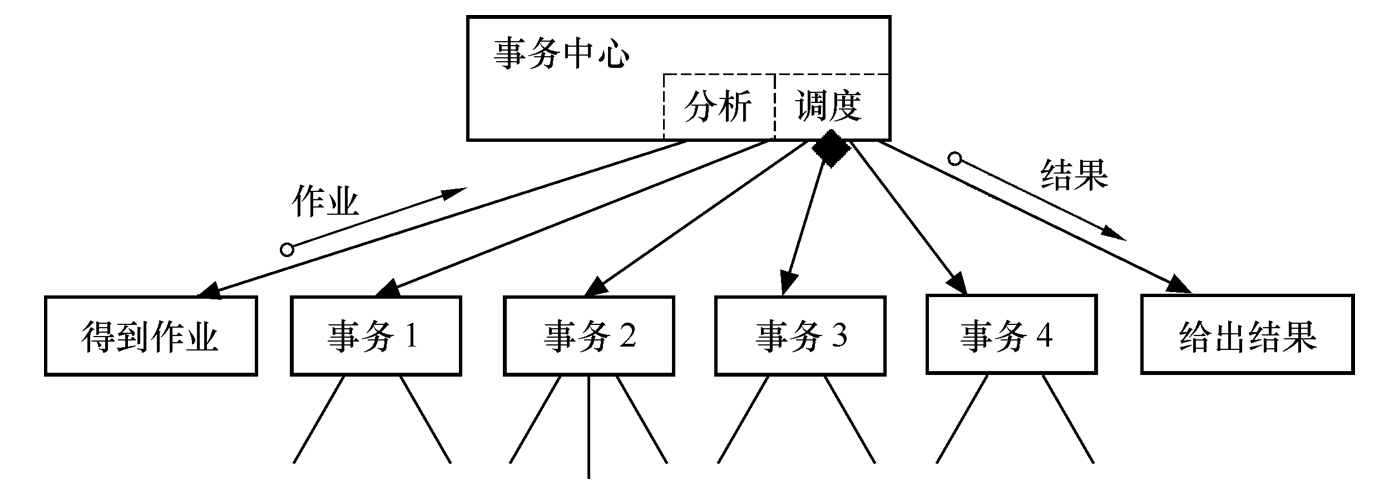
Figure 20: 简化的事务型系统结构图
事务型系统结构图在 数据处理 中经常遇到, 但是更多的是 变换 型与 事务 型系统结构图的结合。
例如,变换型系统结构中的某个 变换 模块本身又具有 事务 型的特点。
3.3. 变换型映射方法
- 通常,系统数据处理问题的 处理流程 总能表示为 变换 型 数据流图 , 进一步可采用 变换 型 映射方法 建立系统的 结构图 。
- 也可能遇到明显的事务数据处理问题,这时可采用 事务 型 映射方法 。
设计人员应当根据 数据流图 的 主要问题类型 , 选择一个 面向全局的 ,即涉及整个软件范围的问题处理类型。 此外,在 局部范围 内是 变换 型还是 事务 型,可 具体研究 ,区别对待。
- 变换分析方法的步骤
- 重画 数据流图 ;
- 区分 有效(逻辑) 输入 、有效(逻辑) 输出 和 中心变换 部分;
- 进行 一级分解 ,设计 上 层模块;
- 进行 二级分解 ,设计 输入 、 输出 和 中心变换 部分的 中 、 下 层模块。
3.3.1. 步骤1 重画数据流图
- 在 需求分析阶段 得到的数据流图侧重于描述 系统如何加工数据 ,
- 而 重画数据流图 的出发点是描述 系统中的数据是如何流动的 。
- 重画数据流图应注意的几个要点
- 以需求分析阶段得到的数据流图为基础重画数据流图时,
- 可以从 物理输入 到 物理输出 ,或者相反。
- 还可以从 顶层加工框 开始, 逐层向下 。
- 在图上 不要 出现 控制逻辑(如 判断 、 循环 )。
用箭头表示的是
数据流 ,而不是 控制流 。 - 不要 去关注系统的 开始 和 终止 。(假定系统在不停地运行)
- 省略 每一个加工框的简单 例外处理 。
- 当数据流 进入 和 离开 一个加工框时,要仔细地 标记 它们, 不要重名 。
- 如有必要,可以 使用 逻辑运算符 (逻辑与,异或)。
- 仔细 检查 每层数据流的 正确性 。
- 以需求分析阶段得到的数据流图为基础重画数据流图时,
3.3.2. 步骤2 在数据流图上区分系统的逻辑输入、逻辑输出和中心变换
在这一步,可以暂时 不考虑 数据流图的一些支流,例如 错误处理 等。 根据经验, 几股数据流汇集 的地方往往是系统的 中心变换 部分。

Figure 21: 数据流图中的输入、中心变换与输出部分
- 逻辑输入 是离 物理输入 端 最远 的但 仍被看作系统输入 的 数据流 ;
- 逻辑输出 是离 物理输出 端 最远 的但 仍被看作系统输出 的 数据流 。
- 从 物理输入 端到 逻辑输入 ,构成系统的 输入部分 ;
- 从 物理输出 端到 逻辑输出 ,构成系统的 输出部分 ;
- 夹在 输入部分 和 输出部分 中间的部分是 中心变换部分 。
3.3.3. 步骤3 进行一级分解,设计系统模块结构的顶层和第一层
自顶向下 设计的关键是找出 系统树形结构图 的 根 或 顶层模块 。
- 首先设计一个 主模块 ,并用程序的名字为它命名,然后将它画在与
中心变换 相对应的位置上。- 作为系统的 顶层 ,它的功能是 调用下一层模块 ,完成系统所要做的各项工作。
- 主模块设计好后,下面的 模块结构 就可以按照 输入 、 中心变换 和 输出 等分支来处理。
模块结构的 第一层 可以这样来设计:
- 为每个 逻辑输入 设计一个 输入模块 ,它的功能是 为主模块提供数据 。
- 为每个 逻辑输出 设计一个 输出模块 ,它的功能是 将主模块提供的数据输出 。
- 为 中心变换 设计一个 变换模块 ,它的功能是 将逻辑输入转换成逻辑输出 。
3.3.4. 步骤4 进行二级分解,设计中、下层模块
这一步工作是 自顶向下、逐步细化 , 为每一个 输入 模块、 输出 模块、 变换 模块设计它们的从属模块。
- 设计下层模块的顺序是 任意 的。
- 但一般是先设计 输入 模块的 下层模块 。
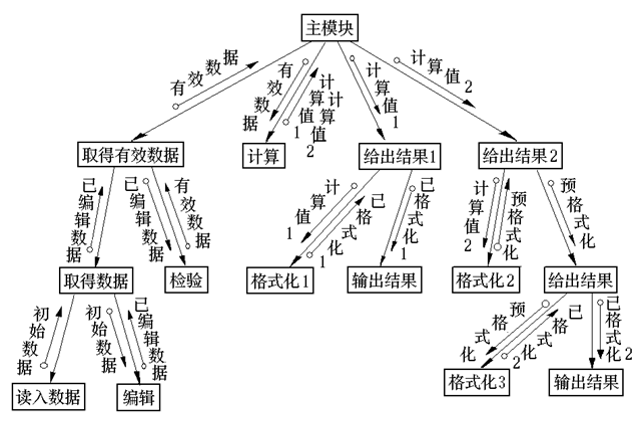
Figure 22: 变换型数据流导出的结构图
3.4. 事务型映射方法
与 变换 分析一样, 事务 分析也是从分析 数据流图 开始, 自顶向下,逐步分解,建立系统的 结构图 。
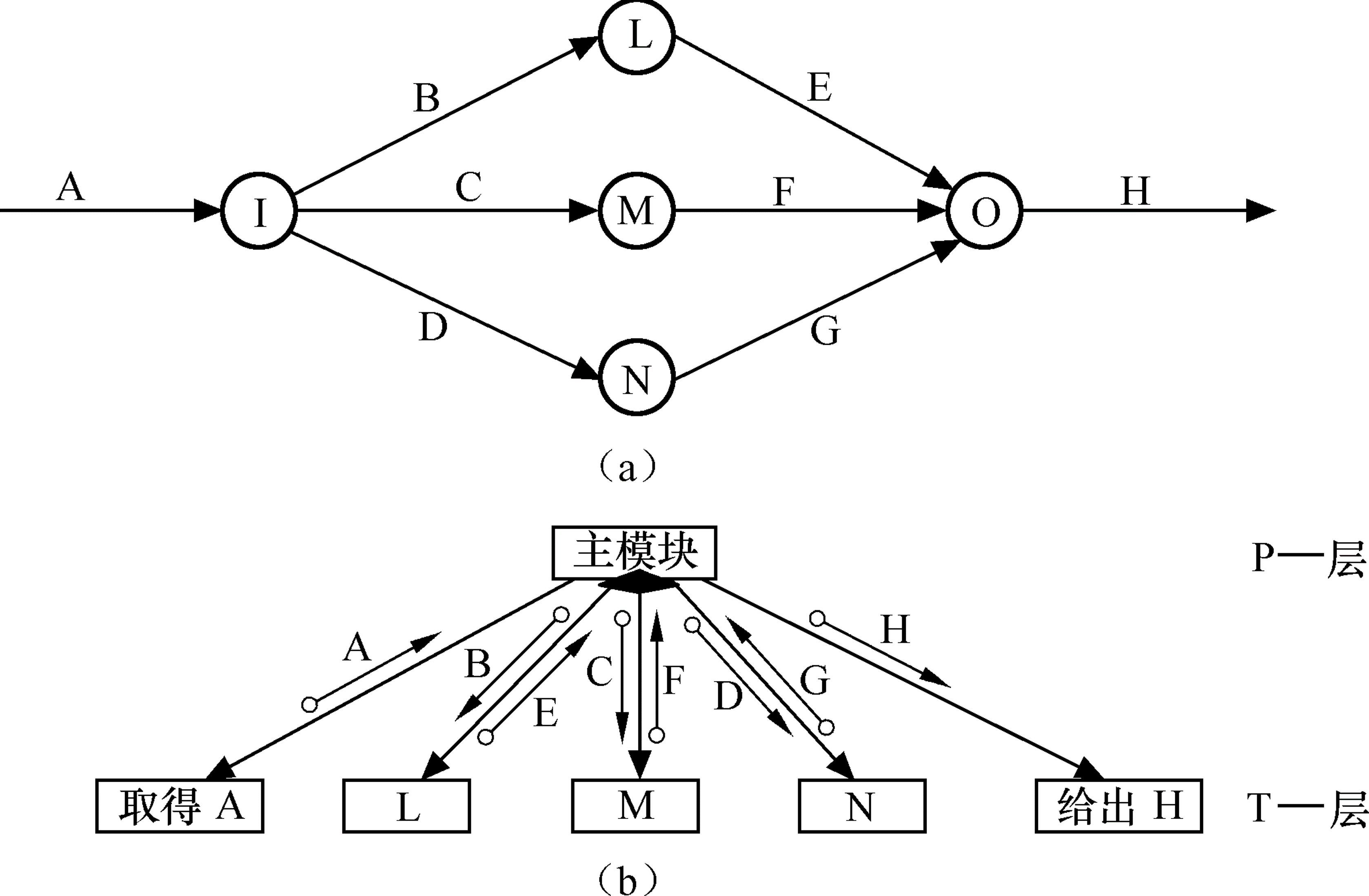
Figure 23: 事务型数据流导出的系统结构图
3.4.1. 事务分析方法的步骤
- 识别事务源 : 利用 数据流图 和 数据词典 ,从 问题定义 和 需求分析 的结果中,找出各种需要处理的 事务 ;
- 规定适当的事务型结构 : 在确定了该数据流图具有事务型特征之后,根据 模块划分理论 ,建立适当的 事务型结构 ;
- 识别各种事务和它们定义的操作 ;
- 注意利用公用模块 ;
- 建立事务处理模块 :对 每一事务 ,或 联系密切的一组事务 ,建立一个 事务处理模块 。
- 对事务处理模块规定它们全部的下层操作模块 ;
- 对操作模块规定它们的全部细节模块 。
3.4.2. 混合型问题的结构图
- 一般,一个大型的软件系统是 变换 型结构和 事务 型结构的 混合结构 。
- 所以,我们通常利用以 变换 分析为 主 , 事务 分析为 辅 的方式进行 软件结构设计 。
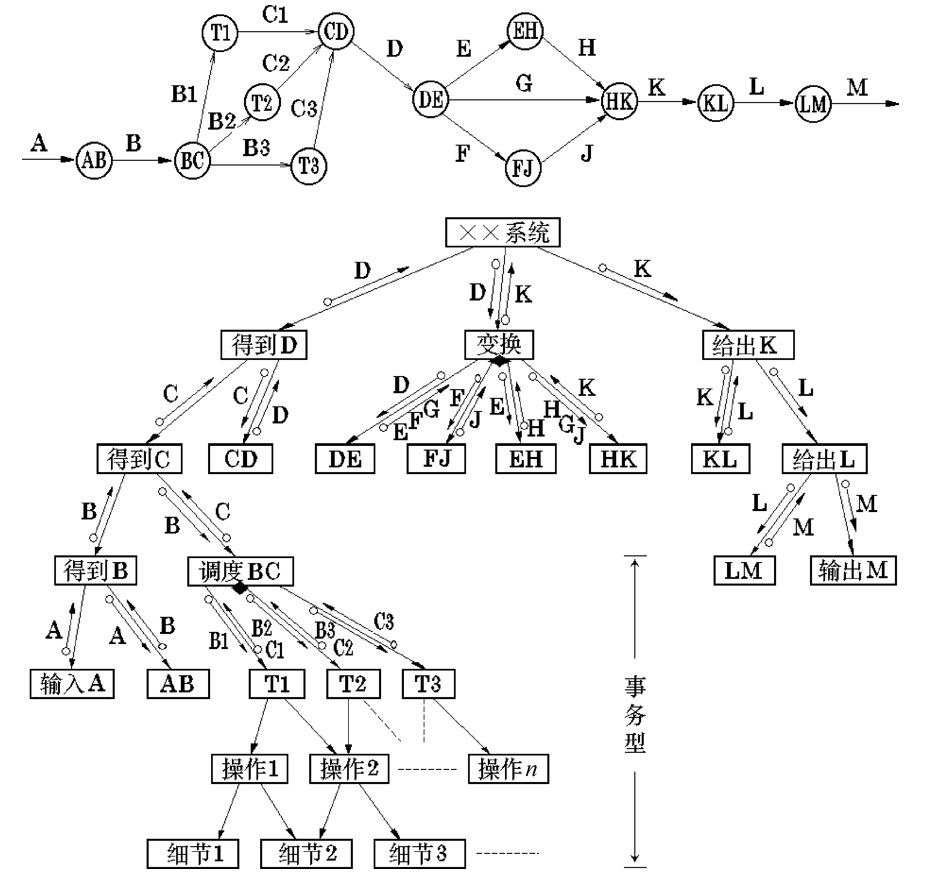
Figure 24: 一个典型的变换-事务混合型问题的结构图
3.5. 模块间的耦合与内聚
3.5.1. 耦合
- 耦合 是程序结构中 各个模块之间 相互 关联 的度量,
它取决于
- 各个模块之间接口的 复杂程度 ;
- 调用模块的 方式 ;
- 通过接口的 信息类型 。
从耦合的机制上进行分类,按照相对的 耦合松紧程度 的排列, Myers\(^*\) 给出的模块间可能的 耦合方式 有 7种 类型, 给设计人员在设计 程序结构 时提供了一个 决策准则 。
\(*\) Stevens, Wayne P.; Myers, Glenford J.; Constantine, Larry LeRoy (June 1974). "Structured design". IBM Systems Journal. 13 (2): 115–139. https://doi.org/10.1147/sj.132.0115.
| 低 | 耦合性 | 高 | ||||
| 非直接耦合 | 数据耦合 | 标记耦合 | 控制耦合 | 外部耦合 | 公共耦合 | 内容耦合 |
| 强 | 模块独立性 | 弱 |
开始时两个模块之间的耦合 不只是一种类型,而是多种类型的混合 。 这就要求设计人员按照Myers提出的方法进行 分析 , 逐步加以 改进 ,以 提高 模块的 独立性 。
- Level 7 内容耦合(Content coupling)
- 如果发生下列情形,两个模块之间就发生了 内容耦合 :
- 一个模块直接 访问 另一个模块的 内部数据
- 一个模块不通过正常入口 转到 另一个 模块内部
- 两个模块有一部分程序 代码重叠 (只可能出现在汇编语言中)
- 一个模块有 多个入口
- 如果发生下列情形,两个模块之间就发生了 内容耦合 :
在内容耦合的情形下,被访问模块的 任何变更 , 或者用 不同的编译器 对它再编译,都会造成 程序出错 。
它一般出现在 汇编语言 程序中, 目前大多数高级程序设计语言已经设计成 不允许 出现 内容耦合 。 这种耦合是 模块独立性最弱 的。
- Level 6 公共耦合(Common coupling)
- 若一组模块都访问同一个公共数据环境,则它们之间的耦合就称为 公共耦合 。
公共的数据环境可以是
- 全局 数据结构
- 共享 的通信区
- 内存的 公共 覆盖区
- ……
- 若一组模块都访问同一个公共数据环境,则它们之间的耦合就称为 公共耦合 。
公共的数据环境可以是
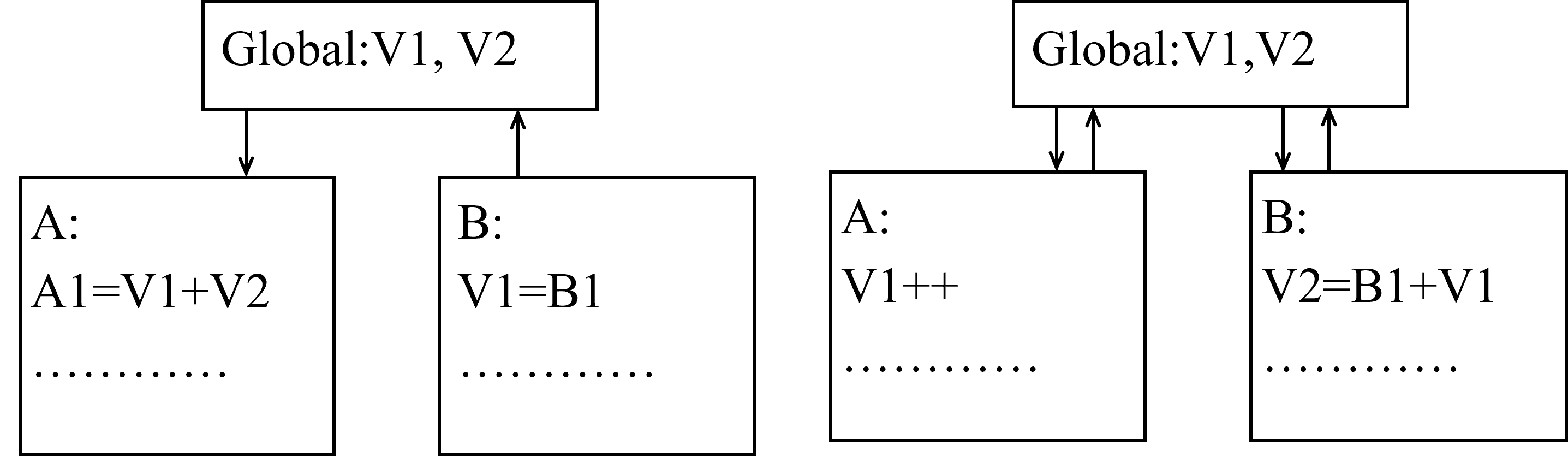
Figure 25: 公共耦合示意图
- Level 5 外部耦合(External Coupling)
若一组模块
- 都访问 同一全局简单变量 而 不是同一全局数据结构 ,
- 而且 不是通过参数表传递该全局变量的信息 ,
则称之为 外部耦合 。
- Level 4 控制耦合(Control coupling)
如果一个模块
- 传递 给另一个模块的 参数 中包含了 控制信息 ,
- 该控制信息用于控制接收模块中的 执行逻辑 ,
则它们之间的耦合称为 控制耦合 。
这种耦合的实质是在 单一接口 上选择 多功能模块 中的 某项功能 。 因此,对被控制模块的 任何修改 ,都会 影响 控制模块。 另外,控制耦合也意味着控制模块 必须知道 被控制模块 内部 的一些 逻辑关系 , 这些都会 降低 模块的 独立性 。
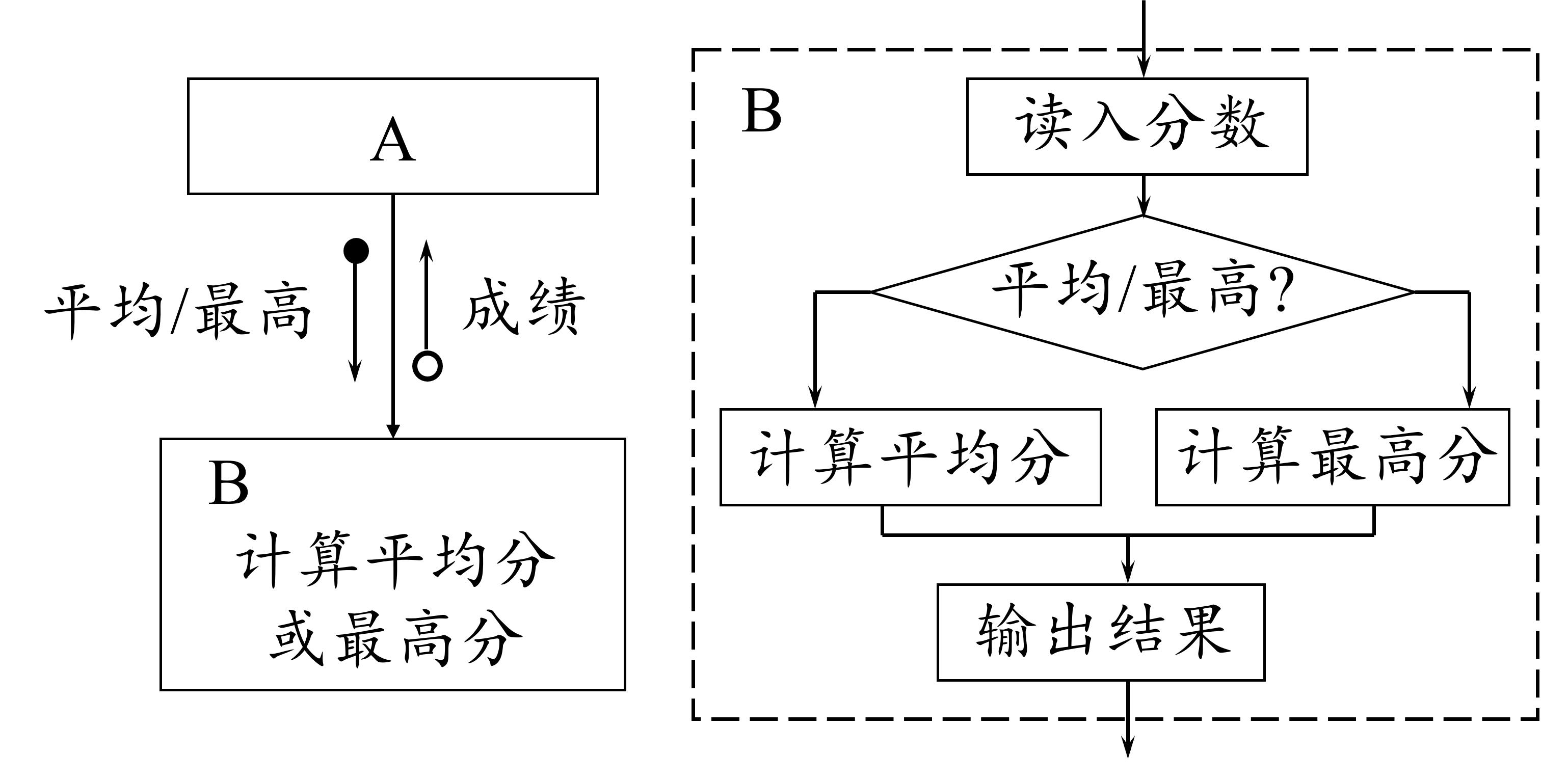
Figure 26: 控制耦合举例
- Level 3 标记耦合(Stamp Coupling)
- 如果一组模块通过 参数表 传递 记录信息 , 则称它们之间的耦合为 标记耦合 。
- 事实上,这组模块共享了这个记录,它是某一数据结构的子结构,而不是简单变量。
这要求这些模块都 必须清楚 该记录的 结构 , 并 按结构要求 对此记录进行 操作 。 在设计中应尽量 避免 这种耦合,它使在数据结构上的操作 复杂化 了。
如果我们采取 信息隐蔽 的方法, 把在数据结构上的操作全部 集中 在一个模块中, 就可以 消除 这种耦合。
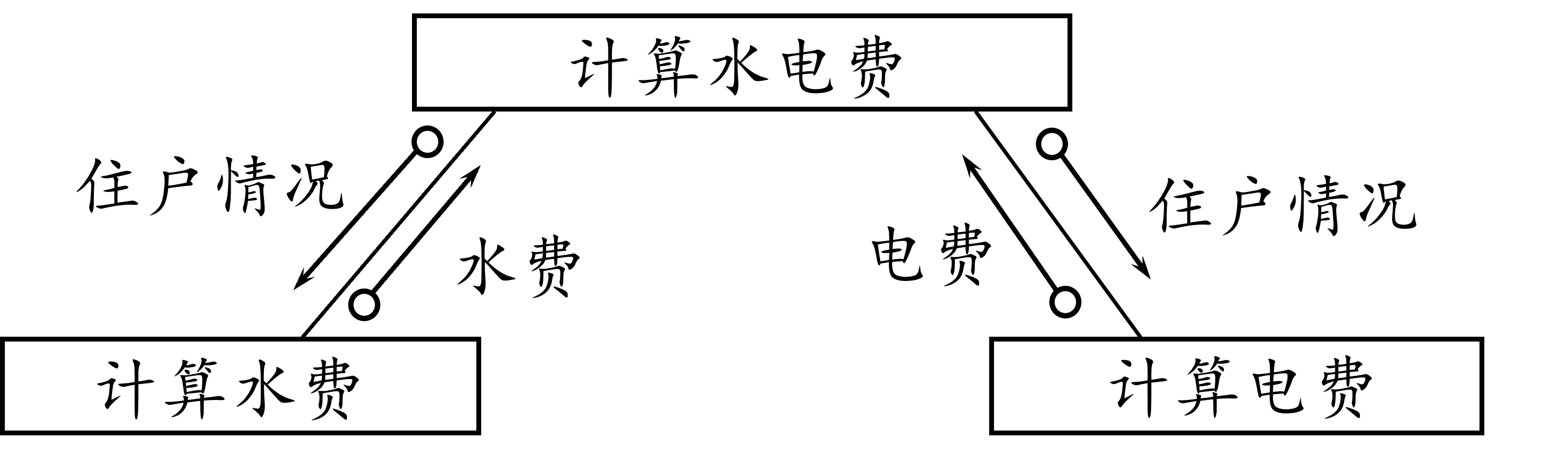
Figure 27: 标记耦合举例
- Level 2 数据耦合(Data coupling)
- 两个模块之间仅通过参数表传递简单数据,则称这种耦合为 数据耦合 。
- 由于限制了 只通过参数表 传递简单数据, 所以按数据耦合开发的程序 界面简单 、 安全可靠 。
- 数据耦合是 松散的耦合 ,模块之间的 独立性 比较 强 。
- 在软件程序结构中至少 必须有这类耦合 。
Figure 28: 改控制耦合为数据耦合举例
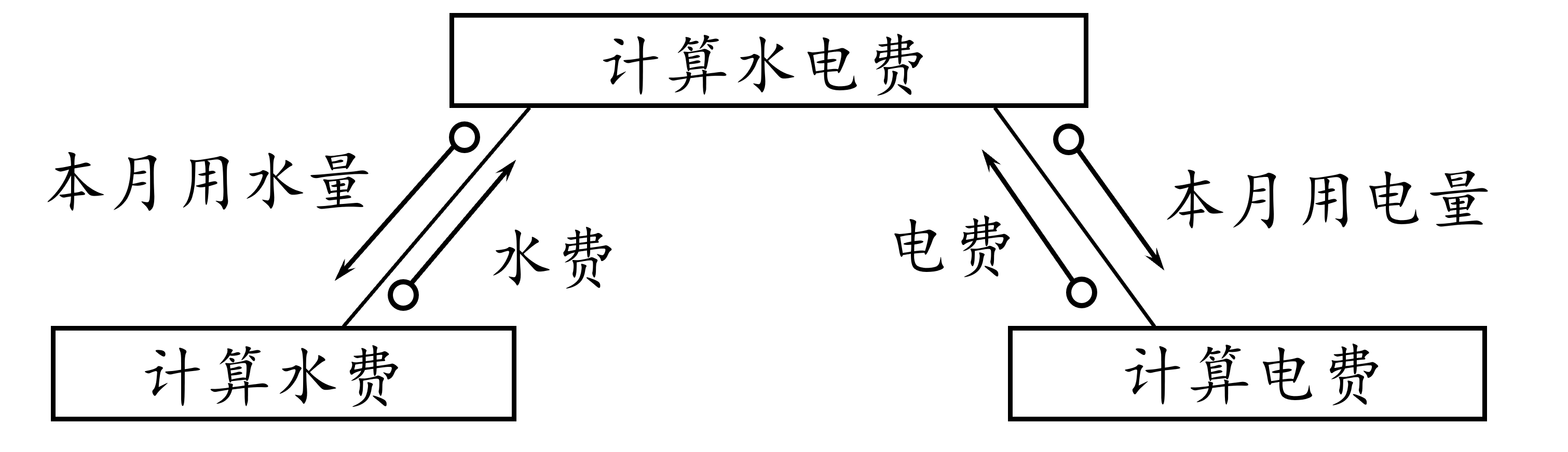
Figure 29: 改标记耦合为数据耦合举例
- Level 1 非直接耦合
- 如果两个模块之间 没有直接关系 , 即它们之间的联系完全是通过 主模块 的 控制 和 调用 来实现的,这就是 非直接耦合 。
- 这种耦合的模块 独立性 最强 。
- 以下说法是否正确?
耦合是不好的,设计模块时不应该让模块间产生耦合。
| 参与人数 | 0 |
|---|---|
| 正确 | 0 |
| 不正确 | 0 |
In software engineering, coupling is
- the degree of interdependence between software modules;
- a measure of how closely connected two routines or modules are;
- the strength of the relationships between modules.
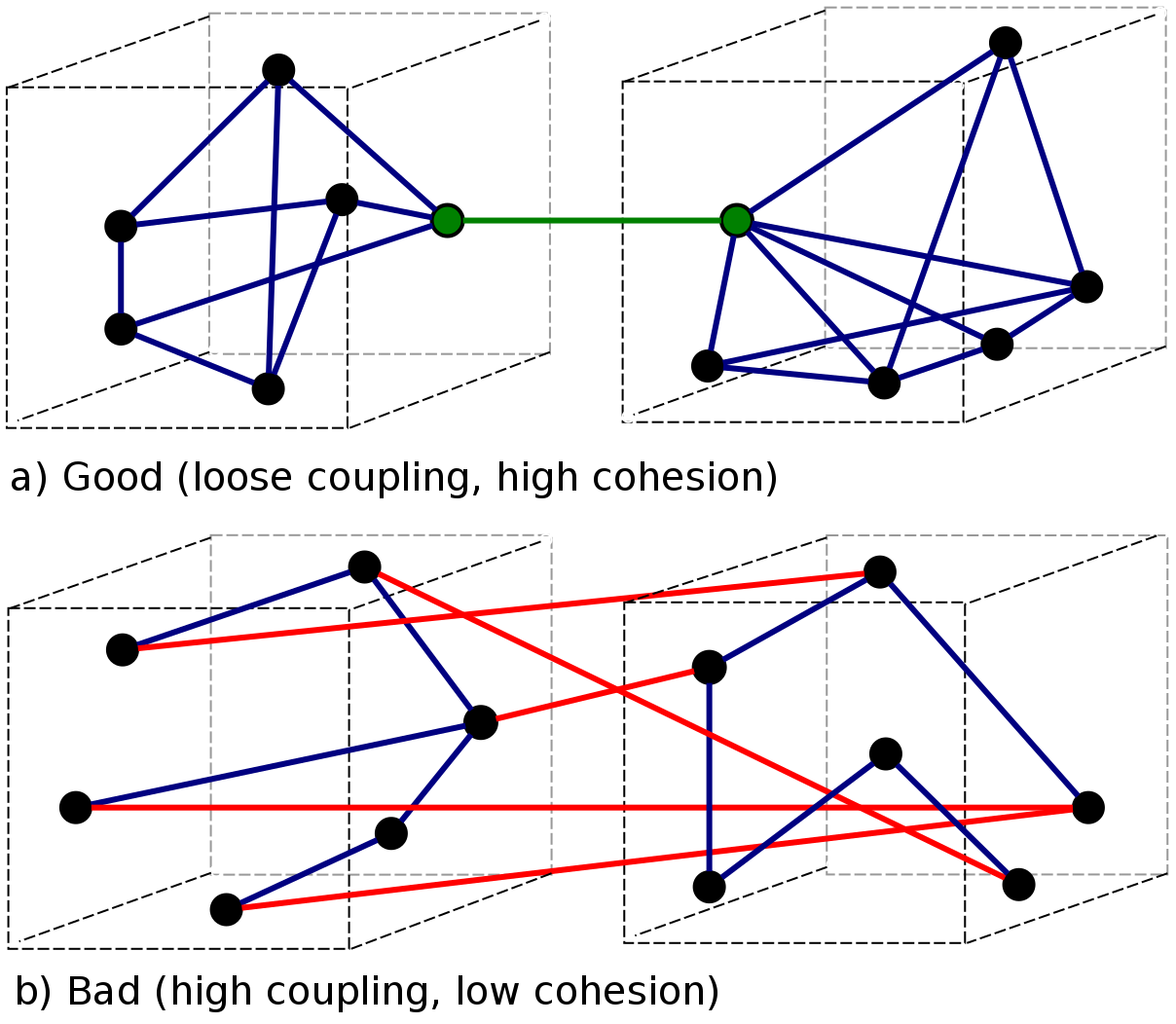
Figure 30: Coupling Vs. Cohesion
- 对耦合的应用原则
- 不在于禁止耦合,而是 充分了解 各种耦合的 特点 与 不足 ,
- 做到能 在需要时 使用它们并 预见 可能产生的 问题 。
耦合是影响软件复杂程度的一个重要因素。
- 应该采取的设计原则
- 尽量使用 数据耦合
- 少用 控制耦合
- 限制 公共环境耦合 的范围
- 完全不用 内容耦合
3.5.2. 内聚
- 内聚 是一个 模块内部各个元素 彼此结合的 紧密程度 的度量。
- 在理想情况下,一个内聚性高的模块应当 只做一件事情 。
- 一般模块的内聚性分为 7种 类型。
| 高 | 内聚性 | 低 | ||||
| 功能内聚 | 信息内聚 | 通信内聚 | 过程内聚 | 时间内聚 | 逻辑内聚 | 巧合内聚 |
| 强 | 模块独立性 | 弱 |
在上面的关系中可以看到,
- 位于 高 端的几种内聚类型 最好 ,
- 位于 中 段的几种内聚类型是 可以接受 的,
- 位于 低 端的内聚类型很不好,一般 不能使用 。
人们总是希望一个模块的内聚类型向 内聚程度高 的方向靠。 模块的内聚 在系统的 模块化设计 中是一个关键的因素。
- Level 1 巧合内聚(Coincidental cohesion)
- 巧合内聚 又称为 偶然内聚 。 当模块内各部分之间 没有联系 ,或者即使有联系,这种联系也很 松散 , 则称这种模块为巧合内聚模块,它是 内聚程度最低 的模块。
例如,一些 没有任何联系 的语句可能在许多模块中重复多次, 程序员为了节省存储,把它们抽出来组成一个新的模块, 这个模块就是 巧合内聚模块 。
- Level 2 逻辑内聚(Logical cohesion)
- 逻辑内聚 模块把几种相关的功能组合在一起,每次被调用时, 由 传送给模块的判定参数 来确定该模块应执行哪一种功能。
例如,根据输入的 控制信息 ,或从文件中读入一个记录, 或向文件中写一个记录。这种模块是 单入口多功能模块 , 例如 错误处理 模块,它接收 出错信号 , 对 不同类型 的错误打印出 不同的错误信息 。
- Level 3 时间内聚(Temporal cohesion)
- 时间内聚 又称为 经典内聚 。 这种模块大多为 多功能模块 ,但模块的各个功能的执行与 时间 有关,
- 通常要求所有功能必须在 同一时间段 内执行。
- 例如 初始化模块 和 终止模块 。
window.onload = function() {
var room = getParameterByName("room") || generateToken(32);
var link = addParam(window.location.href, "room", room );
document.getElementById("room").innerHTML = link;
document.getElementById("room").href = link;
var qrcode = new QRious({ element: document.getElementById('qrcode'), level: 'H', padding: 0, size: 500, value: link, backgroundAlpha: 0 });
document.querySelector("#host").addEventListener('click', function(e) {
e.preventDefault();
RevealSeminar.open_or_join_room(document.getElementById('password').value);
});
}
- Level 4 过程内聚(Procedural cohesion)
- 如果一个模块内的处理是 相关的 ,而且必须以 特定次序 执行, 则称这个模块为 过程内聚 模块。
- 这类模块的内聚程度比 时间内聚 模块的内聚程度更 强 一些。
- 另外,因为过程内聚模块仅包括完整功能的一部分, 所以它的内聚程度仍然 比较低 ,模块间的耦合程度还比较高。
- Level 5 通信内聚(Communicational cohesion)
- 如果一个模块内各功能部分都使用了 相同的输入数据 , 或产生了 相同的输出数据 ,则称之为 通信内聚 模块。
- 通信内聚模块的内聚程度比 过程内聚 模块的内聚程度要 高 , 因为在通信内聚模块中包括了许多 独立的功能 。
- 但是,由于模块中各功能部分使用了 相同的输入/输出缓冲区 , 因而 降低 了整个系统的 效率 。
- Level 6 信息内聚(Informational cohesion)
- 信息内聚 模块完成 多个功能 ,各个功能都在 同一数据结构 上操作, 每一项功能有一个 唯一的入口点 。
例如对某个数据表的 增加 、 修改 、 删除 、 查询 功能, 这个模块将 根据不同的要求 确定该执行哪一个功能。 由于这个模块的所有功能都是基于 同一个数据结构 (数据表), 因此,它是一个信息内聚的模块。
信息内聚模块可以看成是 多个功能内聚模块的组合 ,并且达到 信息的 隐蔽 。 即把某个 数据结构 、 资源 或 设备 隐蔽 在一个模块内, 不为别的模块所知晓。
- Level 7 功能内聚(Functional cohesion)
一个模块中
- 各个部分都是 完成某一具体功能 必不可少的组成部分,
- 或者说该模块中所有部分都是为了 完成一项具体功能 而
协同工作 、 紧密联系 、 不可分割 的,
则称该模块为 功能内聚 模块。
功能内聚模块的 优点 是它们容易 修改 和 维护 , 因为它们的 功能 是 明确的 ,模块间的 耦合 是 简单的 。
功能内聚模块的 内聚程度 最高 。 在把一个系统分解成模块的过程中, 应当 尽可能 使模块达到 功能内聚 这一级。
3.6. 软件模块结构的改进方法
3.6.1. 方法1 模块功能的完善化
一个完整的功能模块,不仅能够完成 指定的功能 , 而且还应当能够告诉使用者完成 任务的状态 ,以及 不能完成的原因 。 也就是说,一个完整的模块应当有以下几部分:
- 执行规定的功能 部分。
- 出错处理 部分。当模块不能完成规定的功能时,必须回送 出错标志 , 向它的调用者 报告 出现这种例外情况的 原因 。
- 如果需要 返回一系列数据 给它的调用者,在 完成数据加工或结束 时, 应当给它的调用者 返回 一个 结束标志 。
所有上述部分,都应当看作是一个模块的 有机组成部分 , 不应分离到其他模块中去 ,否则将会增大模块间的耦合程度。
3.6.2. 方法2 消除重复功能,改善软件结构
在得出系统的初始结构图之后,应当 审查分析 这个结构图。 如果 发现几个模块的功能有相似之处 ,可以加以 改进 。
- 完全相似 :在结构上完全相似,可能只是在数据类型上不一致。 此时可以采取 完全合并 的方法, 只需在 数据类型的描述 上和 变量定义 上加以改进就可以了。
- 局部相似 :此时, 不可以 把两者 合并为一 , 因为这样在合并后的 模块内部 必须设置许多 查询开关 , 势必把模块降低到 逻辑内聚 一级。
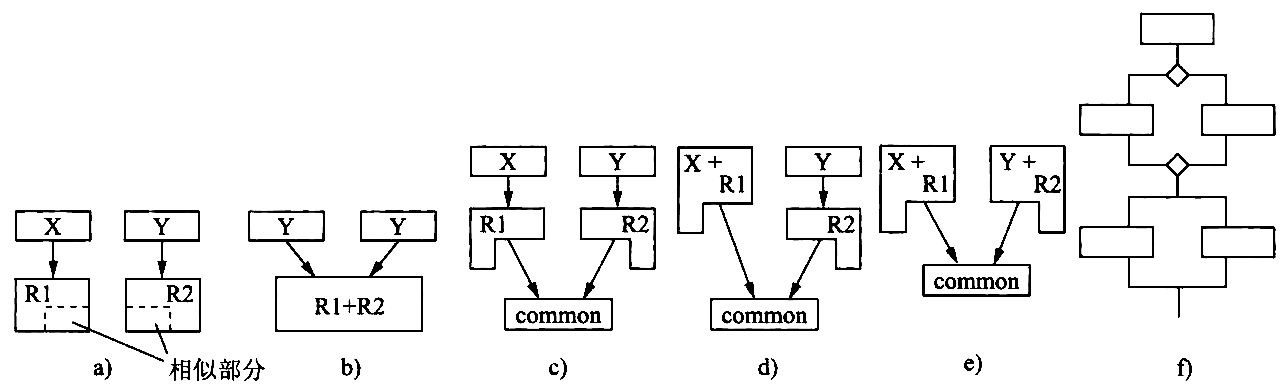
Figure 31: 相似模块的各种合并方案
3.6.3. 方法3 模块的作用范围应在控制范围之内
- 模块的控制范围 包括它 本身 及其所有的 从属模块 。
- 模块的作用范围 是指模块内一个 判定 的 作用范围 , 凡是 受这个判定影响的所有模块 都属于这个判定的 作用范围 。
如果一个判定的 作用范围 包含在 这个判定所在模块的 控制范围 之内, 则这种结构是 简单 的。
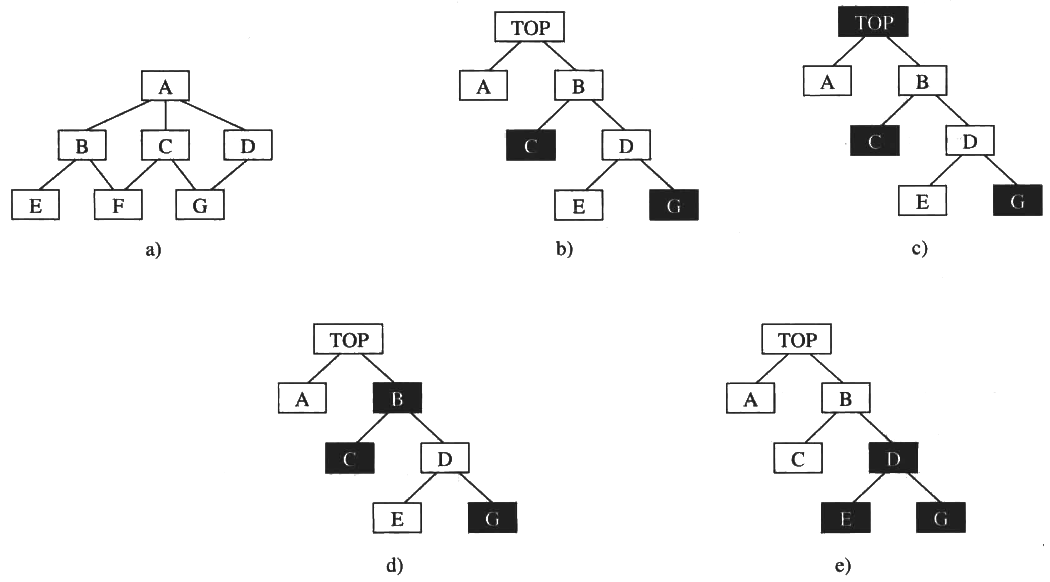
Figure 32: 作用范围与控制范围的关系
- 如果在设计过程中,发现 作用范围 不在 控制范围 内,
可采用如下办法 把作用范围移到控制范围之内 :
- 将判定所在模块合并到父模块中, 使判定处于较高层次 。
- 将 受判定影响的模块下移 到控制范围内。
- 将 判定上移 到层次中较高的位置。
3.6.4. 方法4 尽可能减少高扇出结构,随着深度增大扇入
- 模块的扇出数 是指模块 调用子模块的个数 。 如果一个模块的扇出数 过大 ,就意味着该模块过分 复杂 , 需要协调和控制 过多 的下属模块。 一般说来,出现这种情况是由于 缺乏中间层次 。 所以应当适当 增加中间层次 的控制模块。
- 一个 模块的扇入数 越大 ,则共享该模块的上级模块数目 越多 。 扇入大,是有好处的,但如果一个模块的扇入数太大, 例如超过8,而它又不是公用模块,说明该模块 可能具有多个功能 。 在这种情况下应当对它进一步分析并将其 功能分解 。
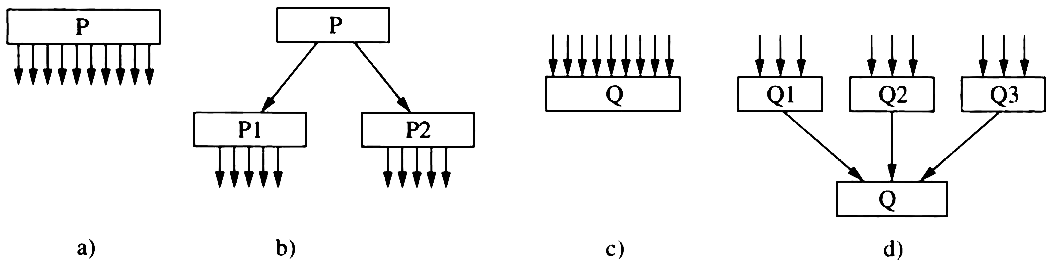
Figure 33: 高扇入和高扇出的分解
3.6.5. 方法5 避免或减少使用病态连接
应限制使用如下3种病态连接:
- 直接病态连接 :模块A 直接从模块B内部取出某些数据 ,或者把某些数据 直接送到模块B内部 。
- 公共数据域病态连接 :模块A和模块B 通过公共数据域 , 直接传送或接收数据 ,而不是通过它们的上级模块。
- 通信模块连接 :模块A和模块B 通过通信模块 传送数据。
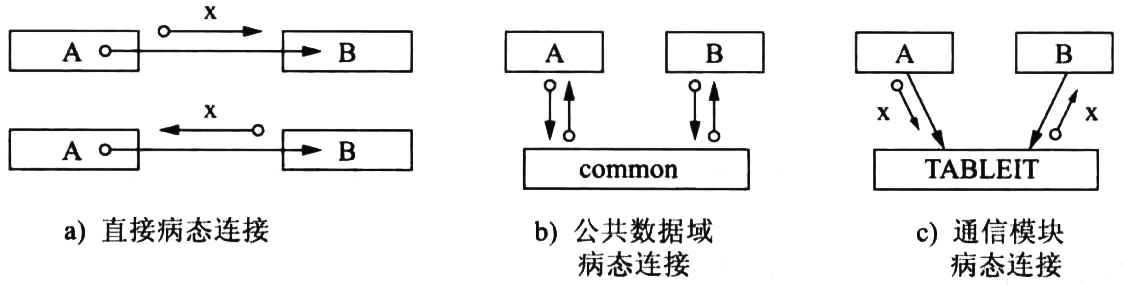
Figure 34: 限制使用的病态连接
3.6.6. 方法6 模块的大小要适中
模块的大小 ,可以用模块中所含 语句的数量的多少 来衡量。
通常规定其语句行数在 50~100 左右, 保持在 一页纸 之内,最多不超过 500行 。
3.6.7. 实例研究
目标
针对第3章的 银行储蓄系统 ,开发软件的 结构图 。
- 第一步
- 对银行储蓄系统的 数据流图 进行 复查 并 精化 , 得到如图所示的数据流图。
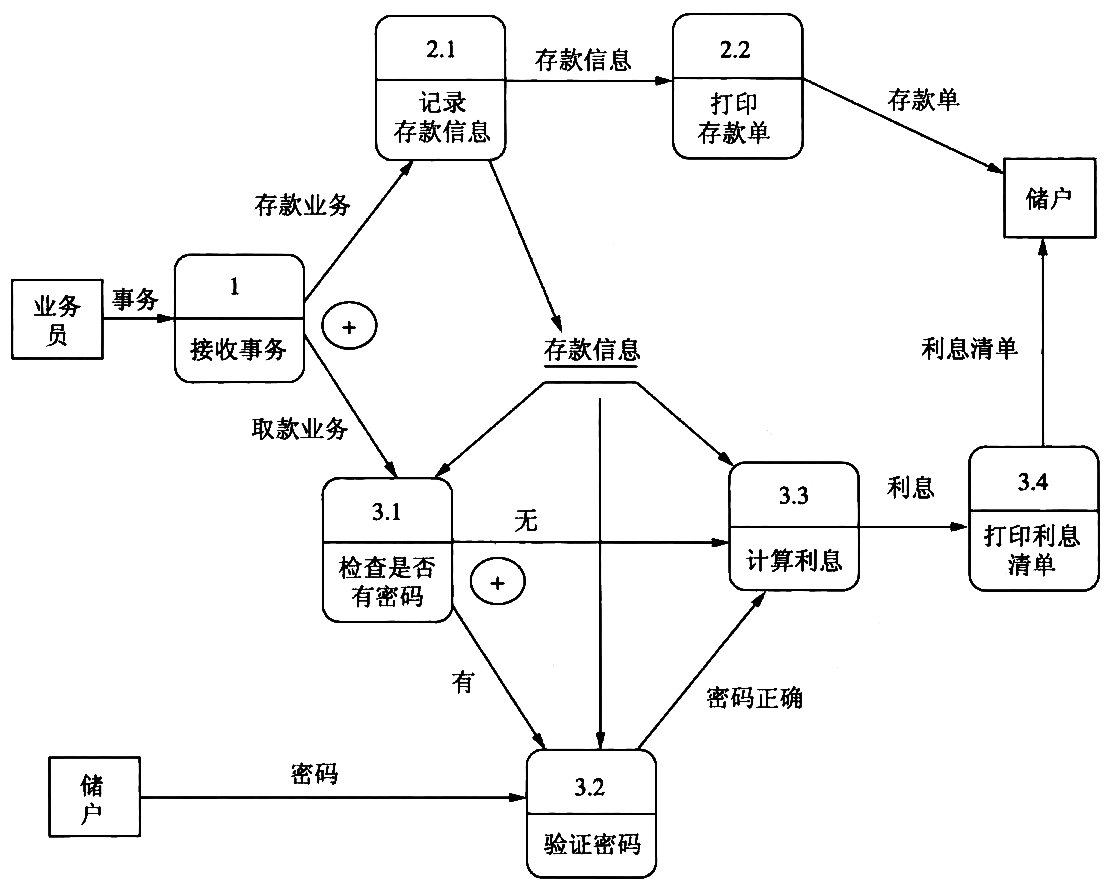
Figure 35: 银行储蓄系统的数据流图
- 第二步
- 确定数据流图具有 变换 特性还是 事务 特性。
通过对第一步得到的 数据流图 进行 分析 , 可以看到整个系统是对 存款 及 取款 两种不同的事务进行处理, 因此具有 事务 特性。
- 第三步
- 确定 输入流 和 输出流 的 边界 ,如图所示。
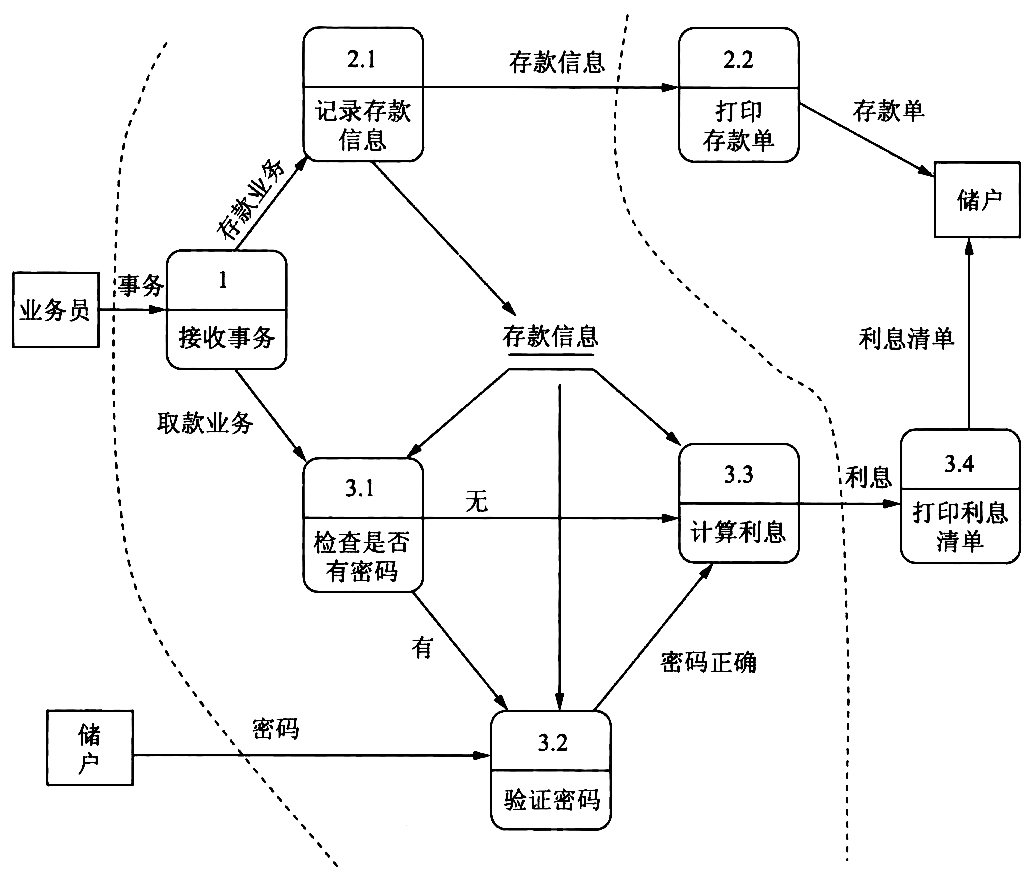
Figure 36: 数据流的边界
- 第四步
- 完成 第一级分解 。分解后的结构图如图所示。

Figure 37: 第一级分解后的结构图
- 第五步
- 完成 第二级分解 。
对第一级分解后的结构图中的 输入数据 、 输出数据 和 调度 模块进行分解, 得到未经精化的 输入结构 、 输出结构 和 事务结构 。

Figure 38: 第二级分解过程
将 输入结构 、 输出结构 和 事务结构 3部分合在一起, 得到初始的软件结构。
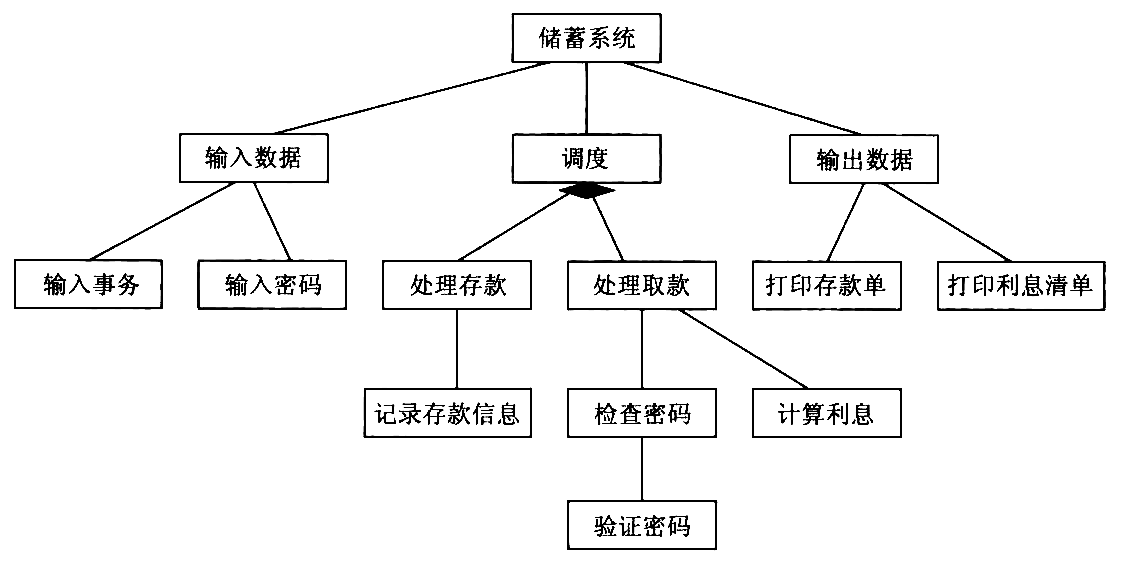
Figure 39: 初始的软件结构
- 第六步
- 对软件结构进行精化。
由于调度模块下 只有两种事务 ,因此,可以将调度模块 合并 到上级模块中,如图所示。
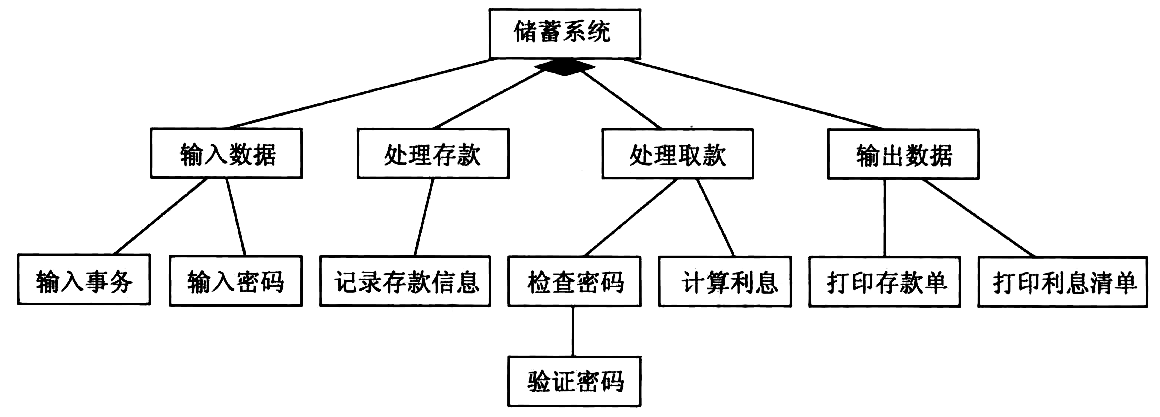
Figure 40: 将调度模块合并到上级模块后的软件结构
检查密码 模块的作用范围不在其控制范围之内 (即 输入密码 模块不在 检查密码 模块的控制范围之内), 需对其进行调整,如图所示。
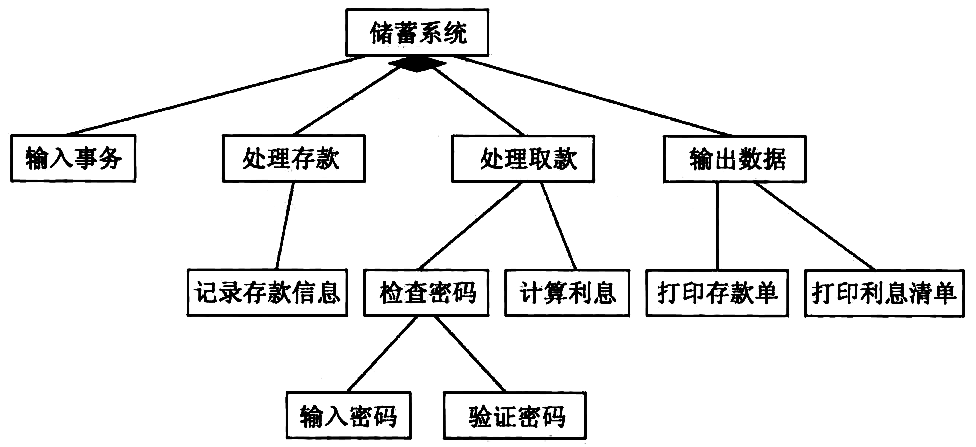
Figure 41: 对输入密码模块进行调整后的软件结构
提高模块的独立性,并对 输入事务 模块进行细化。 也可以将 检查密码 功能合并到其上级模块中。
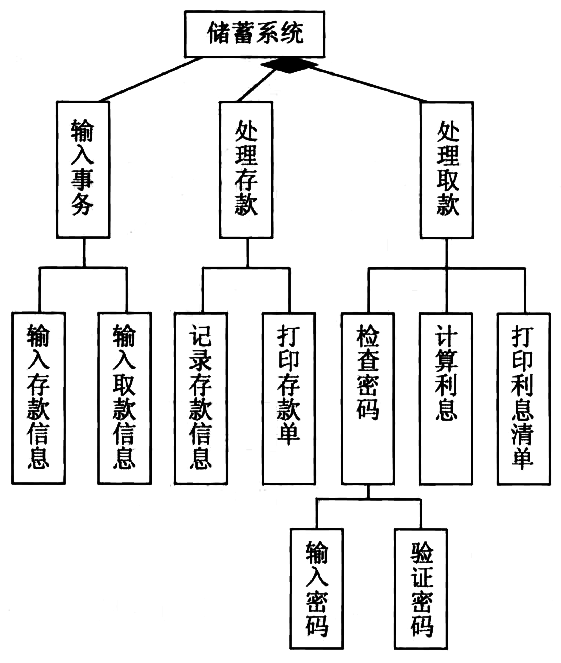
Figure 42: 对模块独立性进行调整后的软件结构
4. 接口设计
4.1. 接口设计概述
接口设计 的依据是 数据流图 中的自动化系统 边界 。
- 接口设计包括的3个方面
- 模块 或软件 构件 间的 接口设计 ;
- 软件 与其他软硬件 系统 之间的 接口设计 ;
- 软件 与人( 用户 )之间的 交互设计 。
人机交互(用户)界面 是 人机交互 的主要方式。
4.2. 人机交互界面
为了设计好人机交互界面,设计者需要:
- 了解 用户界面应具有的 特性 ;
- 认真 研究 使用软件的 用户 ,包括:
- 用户种类 用户是什么人;
- 学习方式 用户怎样学习与新的计算机系统进行交互;
- 工作需求 用户需要完成哪些工作。
- ……
4.2.1. 用户界面应具备的特性
- 可使用性 :
- 使用 简单
- 界面 一致
- 拥有Help 帮助 功能
- 快 速的系统 响应 和 低 的系统 成本
- 具有 容错 能力
- ……
- 灵活性 :考虑到用户的 特点 、 能力 和 知识 水平, 应当使用户接口 满足不同用户的要求 。
- 可靠性 :用户界面的可靠性是指 无故障使用的间隔时间 。 用户界面应能保证用户 正确 、 可靠 地使用系统, 保证 有关程序和数据的 安全性 。
4.2.2. 用户类型
- 外行型 :以前 从未使用 过计算机系统的用户。
- 初学型 :尽管对新的系统 不熟悉 ,但对计算机还有一些使用经验的用户。
- 熟练型 :对一个系统有相当多的经验,能够 熟练 操作的用户。
- 专家型 :这一类用户了解系统的内部构造,有关于系统工作机制的 专业 知识, 具有 维护 和 修改 基本系统的能力。 专家型需要为他们提供能够 修改 和 扩充 系统能力的复杂界面。
4.2.3. 界面设计类型

Figure 43: 界面设计的类型
在选用 界面形式 的时候,应当考虑每种类型的 优点 和 限制 。
- 可以从以下几个方面来考察抉择:
- 使用的难易程度 :对于没有经验的用户,该界面使用的难度有多大。
- 学习的难易程度 :学习该界面的命令和功能的难度有多大。
- 操作速度 :在完成一个指定操作时,该界面在操作步骤、击键和反应时间等方面效率有多高。
- 复杂程度 :该界面提供了什么功能,能否用新的方式组合这些功能以增强界面的功能。
- 控制 :人机交互时,是由计算机还是由人发起和控制对话。
- 开发的难易程度 :该界面设计是否有难度,开发工作量有多大。
4.2.4. 设计详细的交互
- 人机交互的设计有若干准则,包括以下内容:
- 一致性 : 采用 一致的术语 、 一致的步骤 和 一致的活动 。
- 操作步骤少 :使击键或点击鼠标的 次数 减到最少, 甚至要 减少 做某些事所需的下拉菜单的 距离 。
- 不要哑播放 :每当用户要等待系统完成一个动作时, 要 给出 一些 反馈 信息,说明工作正在进展及取得了多少进展。
- 提供Undo功能 :用户的操作错误很难免,对于基本的操作应 提供 恢复 功能,或至少是部分恢复。
- 减少人脑的记忆负担 : 不应该要求 人们从一个窗口中 记住 某些信息,然后在另一个窗口中使用。
- 提高学习效率 :为高级特性 提供 联机 帮助 ,以便用户在需要时容易找到。
5. 数据设计
数据 是 软件系统 中的重要组成部分, 在 设计阶段 必须对要存储的 数据 及其 结构 进行设计。
- 目前,大多数设计者都会采用成熟的 关系数据库管理系统(DBMS) 来 存储 和 管理 数据,由于关系数据库已经相当成熟, 如果应用开发中选择关系数据库, 在数据存储和管理方面可以省去很大的开发工作量。
- 虽然如此, 在某些情况下,选择文件保存方式仍有其优越性 。
5.1. 文件设计
以下几种情况适合于选择文件存储:
- 数据量较大的非结构化数据 :多媒体信息
- 数据量大、信息松散 的情况:历史记录、档案文件等
- 非关系层次化数据 :系统配置文件
- 对数据的存取速度要求极高 的情况
- 临时存放的数据
- 文件设计的主要工作就是根据
- 使用要求
- 处理方式
- 存储的信息量
- 数据的活动性
- 所能提供的设备条件
- ……
- 来
- 确定 文件 类别 ,
- 选择 文件 媒体 ,
- 决定 文件 组织 方法,
- 设计 文件记录 格式 ,
- 估算 文件的 容量 。
- 文件的分类(根据文件的特性)
- 顺序文件 :这类文件分两种,一种是 连续文件 ,另一种是 串联文件 。
- 直接存取文件 :可根据记录 关键字 的值,通过 计算 直接得到记录的 存放地址 。
- 索引顺序文件 :其基本数据记录按 顺序文件 组织, 记录排列顺序必须按关键字值 升序 或 降序 安排, 且具有 索引 部分,索引部分也按同一关键字进行索引。
- 分区文件 :这类文件主要用于存放程序。 它由若干称为成员的顺序组织的 记录组 和 索引 组成。 每一个成员就是一个程序,由于各个程序的长度不同,所以各个成员的大小也不同, 需要利用索引给出各个成员的 程序名 、开始存放 位置 和 长度 。
- 虚拟存储文件 :这是基于操作系统的 请求页式存储管理 功能而建立的 索引顺序文件 。
- 此外,还有适合于侯选属性查找的 倒排文件 等等。
5.2. 数据库设计
- 数据库的分类(根据数据库的组织)
- 网状 数据库
- 层次 数据库
- 关系 数据库
- 面向对象 数据库
- 文档 数据库
- 多维 数据库
- ……
关系数据库 最成熟,应用也最广泛,一般情况下,大多数设计者都会选择关系数据库。 在结构化设计方法中,很容易将 结构化分析阶段 建立的 实体–关系 模型 映射 到关系数据库中。
- 数据对象(实体)的映射
- 一个数据对象(实体)可以映射为一个表或多个表,
当分解为多个表时,可以采用 横切 和 竖切 的方法。
- 横切 常用于记录与 时间 相关的对象。 往往在主表中只记录最近的对象,而将以前的记录转到对应的历史表中。
- 竖切 常用于 实例 较 少 而 属性 很 多 的对象。 通常将经常使用的属性放在主表中,而将其他一些次要的属性放到其他表中。
- 一个数据对象(实体)可以映射为一个表或多个表,
当分解为多个表时,可以采用 横切 和 竖切 的方法。
- 关系的映射
- 一对一关系的映射 : 可以在两个表中都引入 外键 ,进行 双向导航 。 也可以将两个数据对象组合成一张单独的表。
- 一对多关系的映射 : 可以将关联中的 一 端毫无变化地映射到 一张表 , 将关联中的 多 端上的数据对象映射到带有 外键 的 另一张表 , 使外键满足 关系引用 的完整性。
- 多对多关系的映射 : 为了表示多对多关系,关系模型必须引入一个 关联表 , 将两个数据实体之间的 多对多 关系 转换 成两个 一对多 关系。
6. 过程设计
概要设计 任务完成后,进入 详细设计 阶段,即 过程设计 阶段。
- 过程设计阶段的任务
- 决定 各个模块的实现 算法 ,
- 并 使用 过程描述工具 (表达 过程规格说明 的工具)精确地 描述 这些 算法 。
- 过程描述工具的3个类别
- 图形工具 : 把过程的 细节 用 图形 方式描述出来,如 程序流程图 、 N-S图 、 PAD 、 决策树 ……
- 表格工具 :
用一张表来表达过程的细节。
这张表列出了各种可能的 操作 及其相应的 条件 ,
即描述了 输入 、 处理 和 输出 信息,
如 决策表 。 - 语言工具 :用某种类高级语言(也称为 伪代码 )来描述过程的细节, 如很多数据结构教材中使用 类Pascal 、 类C语言 来描述算法。
6.1. 结构化程序设计
由于软件 开发 和 维护 中存在的一系列严重问题, 导致 20世纪60年代 爆发了 软件危机 。 很多人将软件危机的一个原因归咎于 GOTO语句的滥用 , 由此引发了关于GOTO语句的争论。
- 1965年, E. W. Dijkstra 在一次会议上提出,应当将GOTO语句从高级语言中取消。
- 1966年, Bohm 和 Jacopini 证明了任何 单入口 、 单出口 的 没有死循环 的程序 都能由3种 最基本的控制结构 构造出来:
- 顺序结构
- 选择结构
- 循环结构
- 20世纪70年代, E. W. Dijkstra 提出了程序要实现结构化的主张, 并将这一类程序设计称为 结构化程序设计(structured programming) 。
- 结构化程序设计的主要原则
- 使用语言中的 顺序 、 选择 、 重复 等有限的 基本控制结构 表示程序逻辑。
- 选用的控制结构只准许有 一个 入口 和 一个 出口 。
- 程序语句组成容易识别的块(Block),每块只有 一个 入口 和 一个 出口 。
- 复杂结构应该用 基本控制结构 进行 组合嵌套 来实现。
- 语言中没有的控制结构,可用一段等价的程序段 模拟 , 但要求该程序段在整个系统中应 前后一致 。
- 严格控制GOTO语句,仅在下列情形才可使用:
- 用 非结构化的程序设计语言 去实现 结构化的构造 。
- 若 不使用GOTO语句 就会使程序 功能模糊 。
- 在某种可以 改善 而 不是损害 程序 可读性 的情况下。 例如,在 查找结束 时, 文件访问结束 时, 出现错误情况要从循环中转出 时, 使用 布尔变量 和 条件结构 来实现就 不如用GOTO语句来得简洁易懂 。
- 在程序设计过程中, 尽量采用 自顶向下 (top-down)和 逐步细化 (stepwise refinement)的原则, 由粗到细,一步步展开。
6.2. 程序流程图
程序流程图(program flowchart) 也称为 程序框图 , 是软件开发者最熟悉的 算法表达工具 。
- 早期的流程图存在一些缺点。特别是表示 程序控制流程 的 箭头 , 使用的 灵活性 极大,程序员可以不受任何约束,随意 转移控制 , 不符合结构化程序设计的思想。
- 为使用流程图描述结构化程序,必须 限制 流程图只能使用一些基本控制结构。
- 流程图只允许使用的5种基本控制结构
- 顺序型 :几个连续的加工步骤依次排列构成。
- 选择型 :由某个逻辑判断式的取值决定选择两个加工中的一个。
- 先判定(while)型循环 :在循环控制条件成立时,重复执行特定的加工。
- 后判定(until)型循环 :重复执行某些特定的加工,直至控制条件成立。
- 多情况(case)型选择 :列举多种加工情况,根据控制变量的取值,选择执行其一。
- 流程图的基本控制结构及嵌套实例
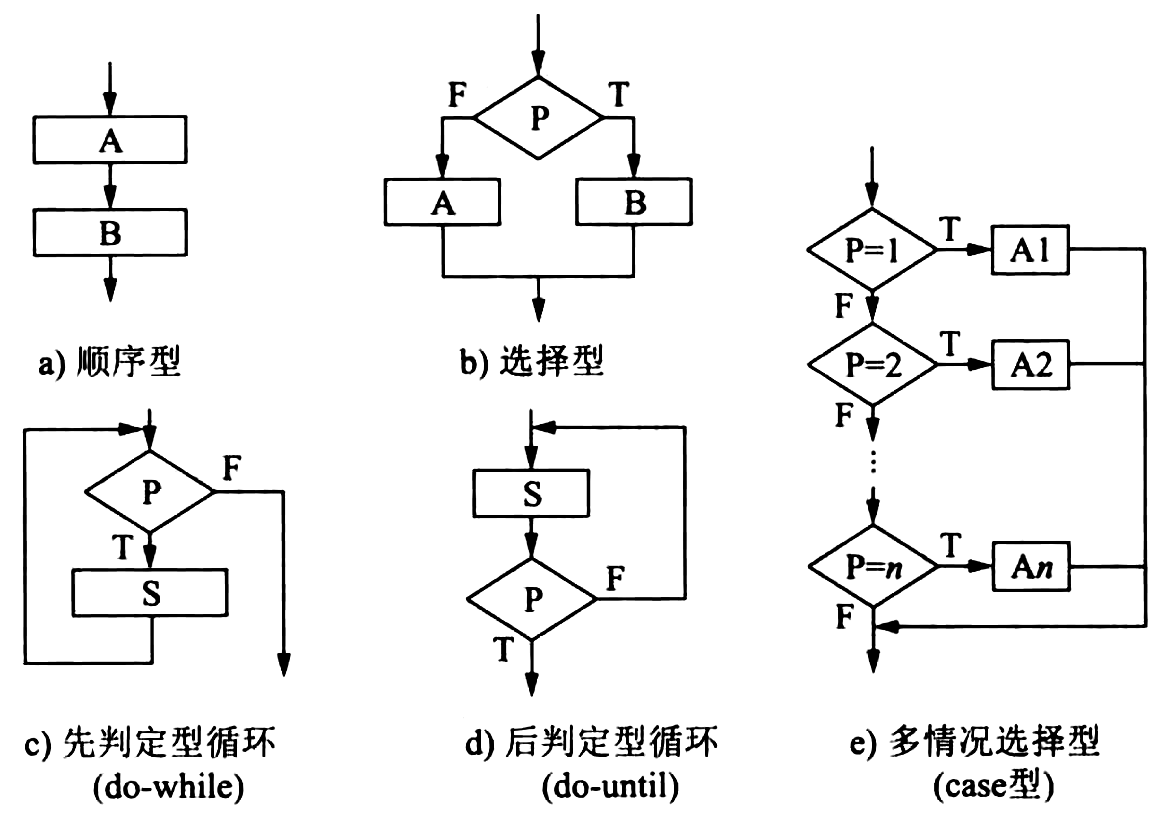
Figure 44: 流程图的基本控制结构
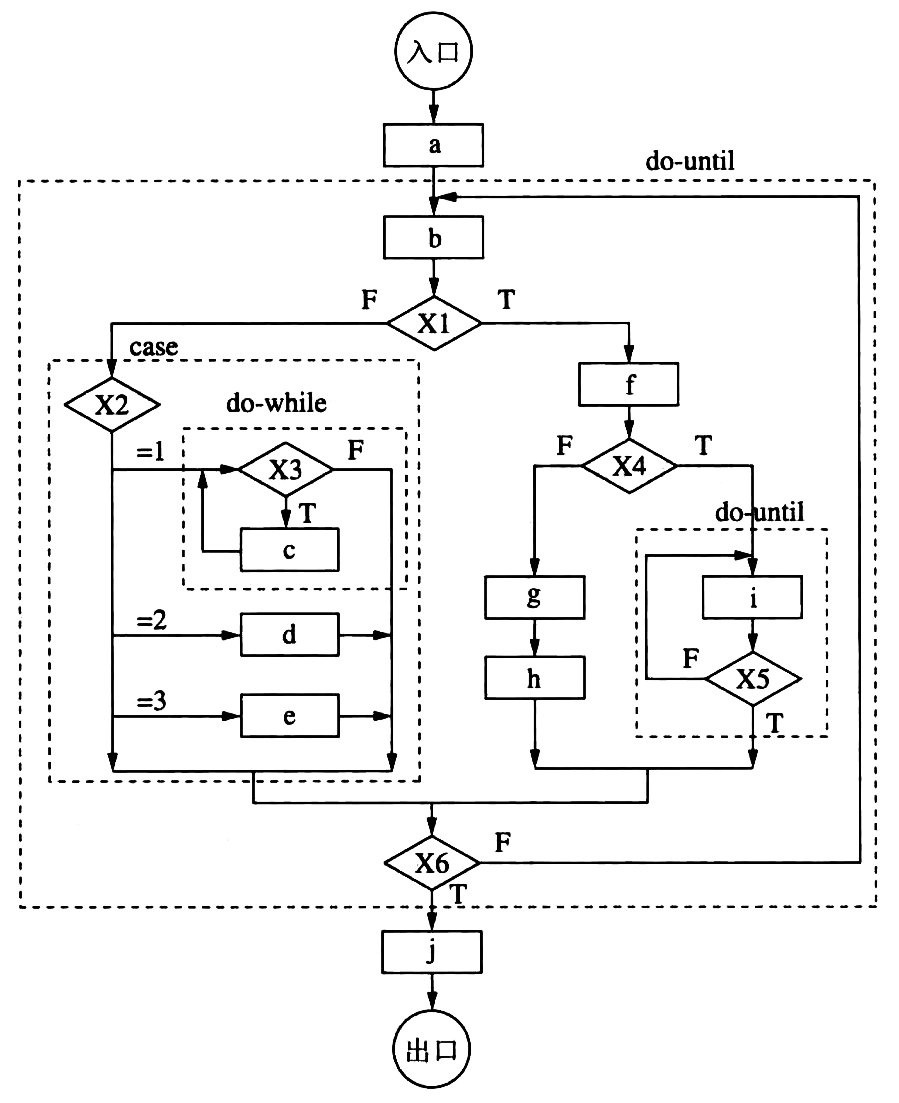
Figure 45: 嵌套构成的流程图实例
- 流程图的符号及含义

Figure 46: 标准程序流程图的规定符号
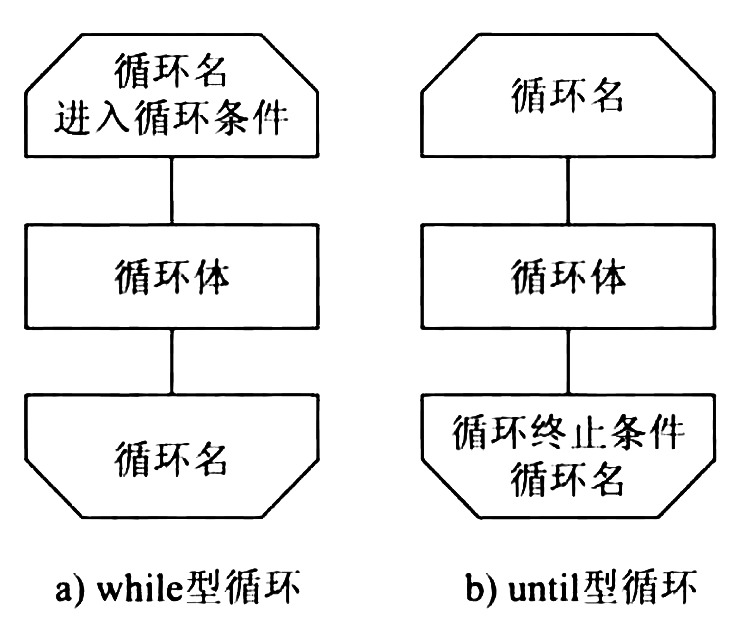
Figure 47: 循环的标准符号
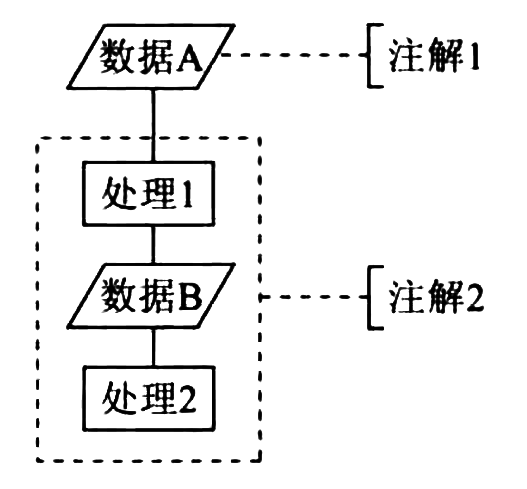
Figure 48: 注解符的使用
- 使用流程图表示多选择判断的方式
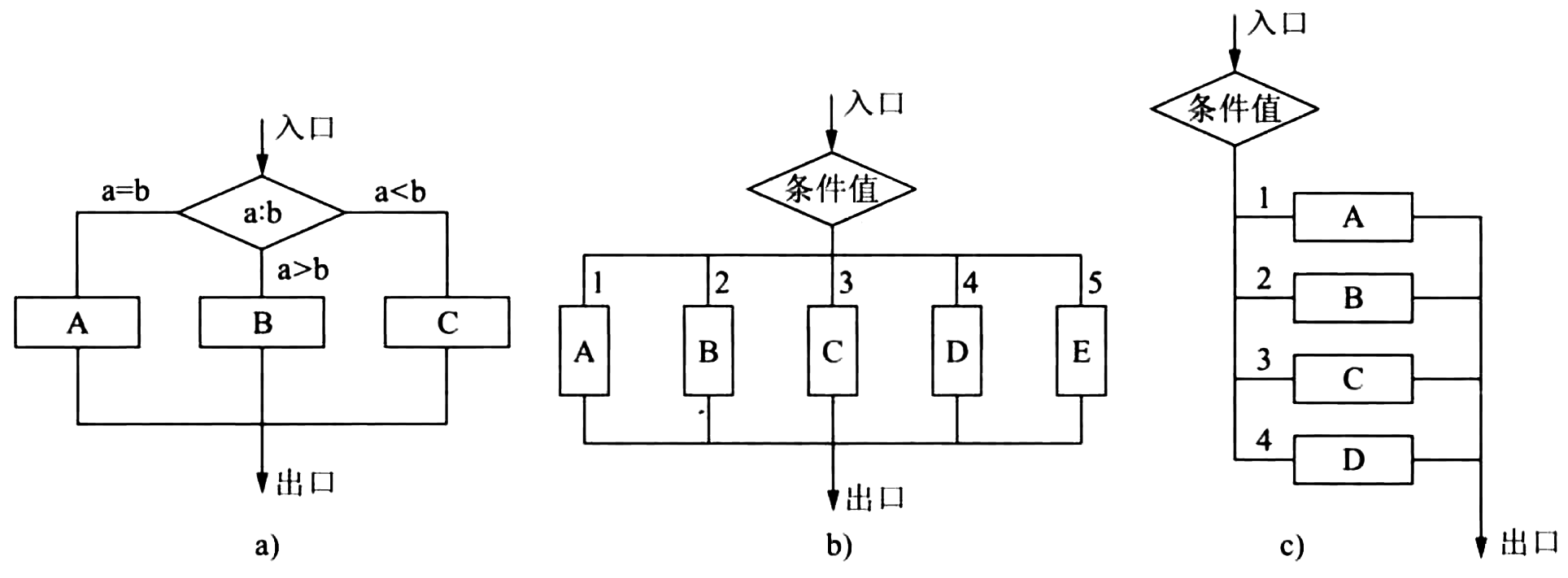
Figure 49: 多选择判断
6.3. N-S图
Nassi 和 Shneiderman 提出了一种符合 结构化程序设计原则 的
图形描述工具 ,
叫做 盒图(box-diagram) ,也叫做 N-S图 。
- 在N-S图中,为了表示 5种 基本控制结构 ,规定了 5种 图形构件 。
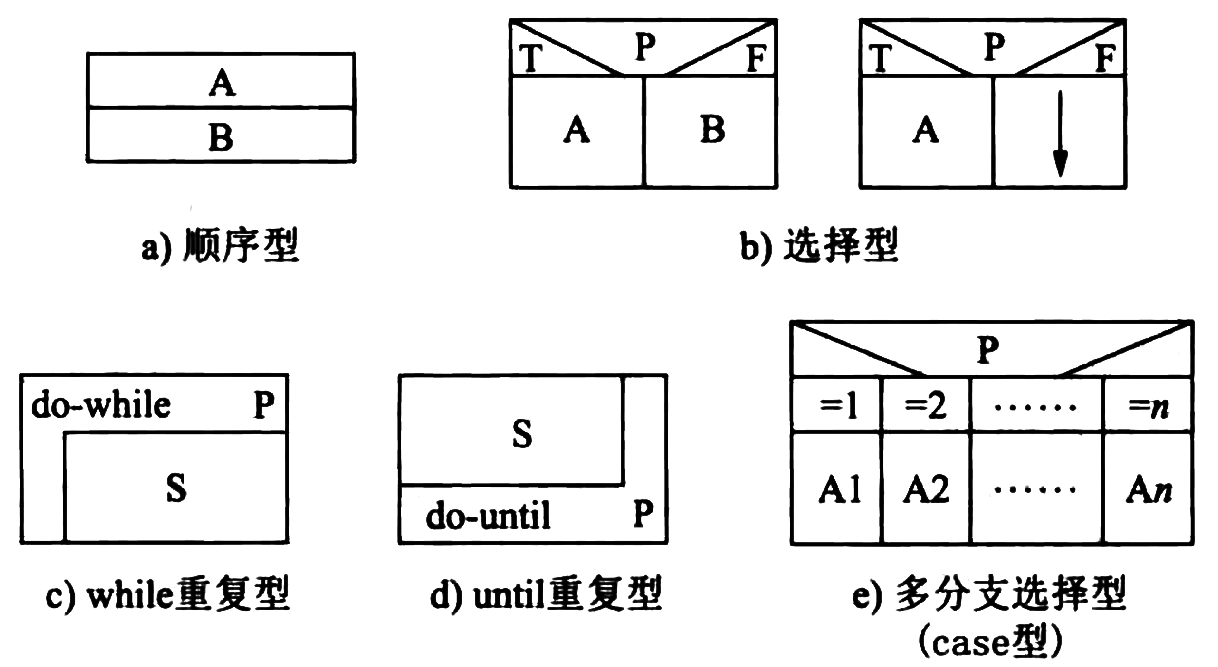
Figure 50: N-S图的5种基本控制结构
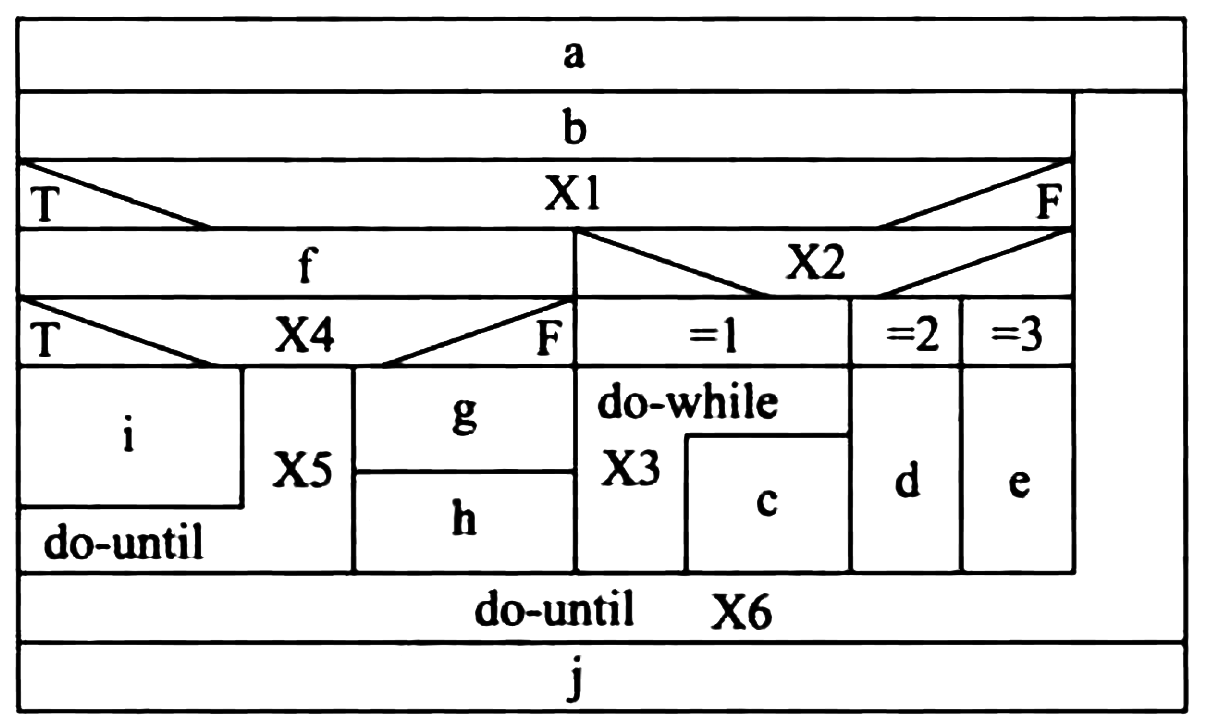
Figure 51: N-S图的实例
- N-S图的特点
- 图中每个矩形框(除case构造中表示条件取值的矩形框外) 都是 明确定义 了的 功能域 (即一个特定控制结构的作用域),以图形表示,清晰可见。
- 它的 控制转移 不能任意规定 ,必须遵守结构化程序设计的要求。
- 很容易 确定 局部数据和(或)全局数据的 作用域 。
- 很容易 表现 嵌套关系 ,也可以 表示 模块的 层次结构 。
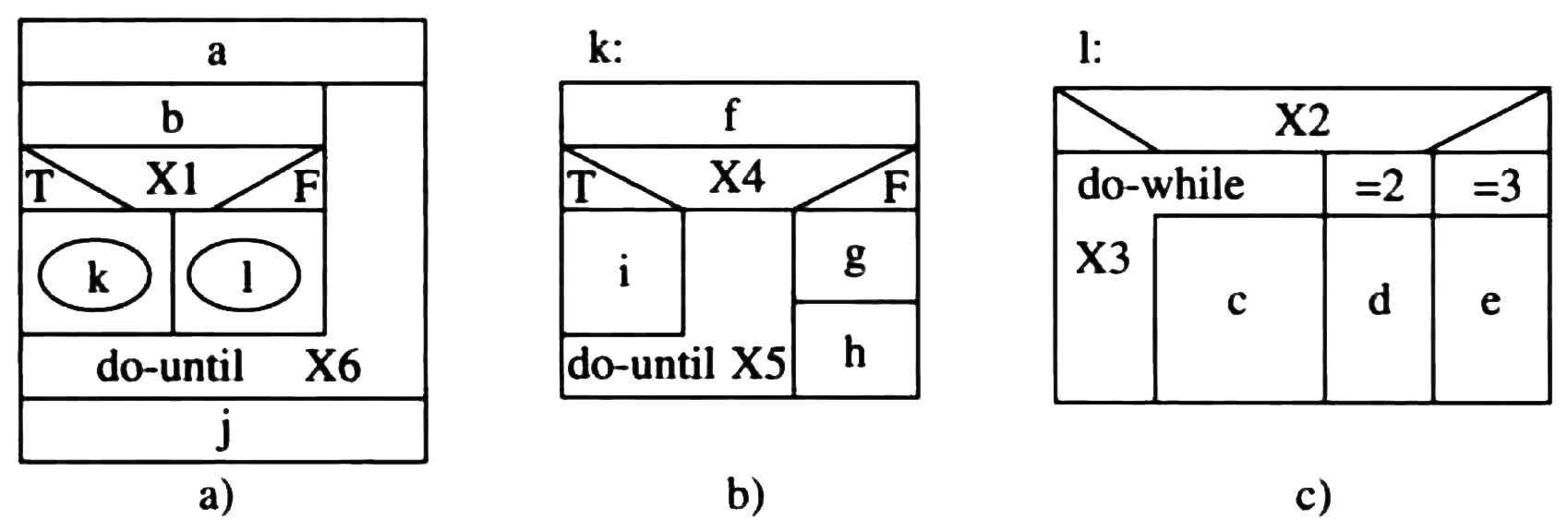
Figure 52: N-S图的扩展表示
6.4. PAD
问题分析图(Problem Analysis Diagram, PAD) 是日本日立公司提出的、 由 程序流程图 演化来的用 结构化程序设计 思想表现程序逻辑结构的 图形工具 。
- PAD也 设置 了 5种 基本控制结构的图式,并 允许 递归 使用。
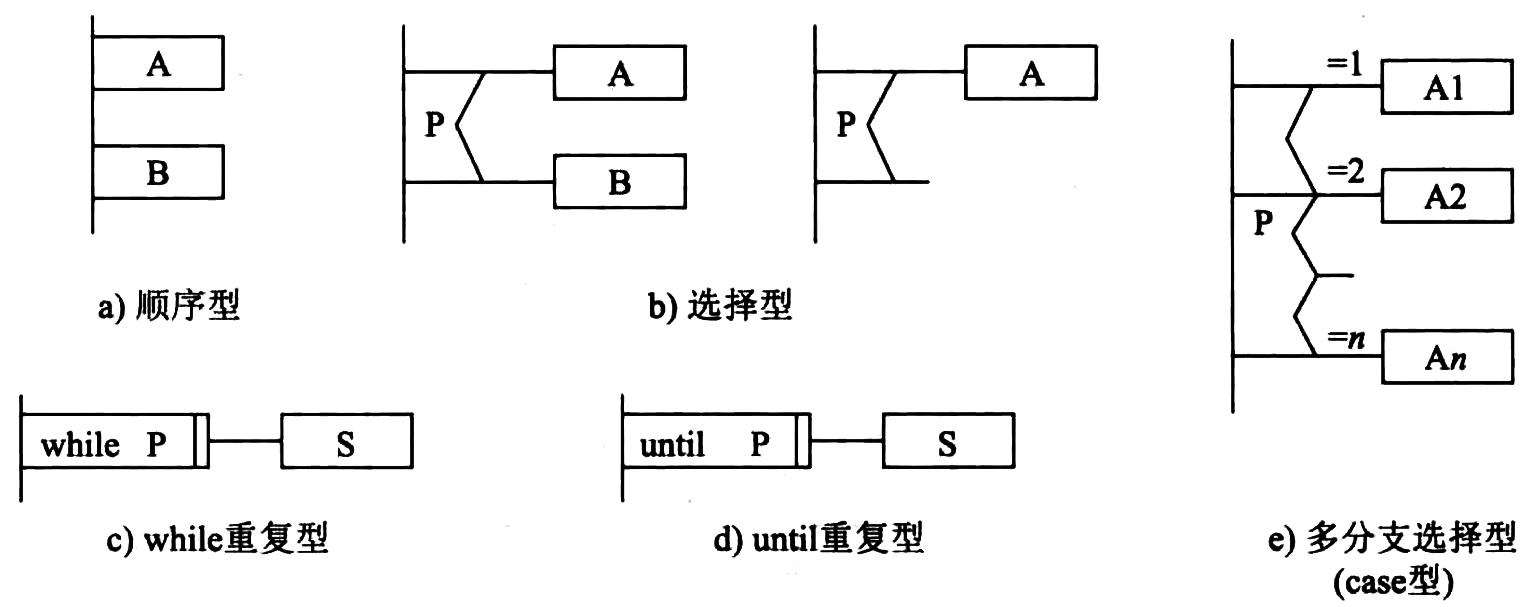
Figure 53: PAD的基本控制结构
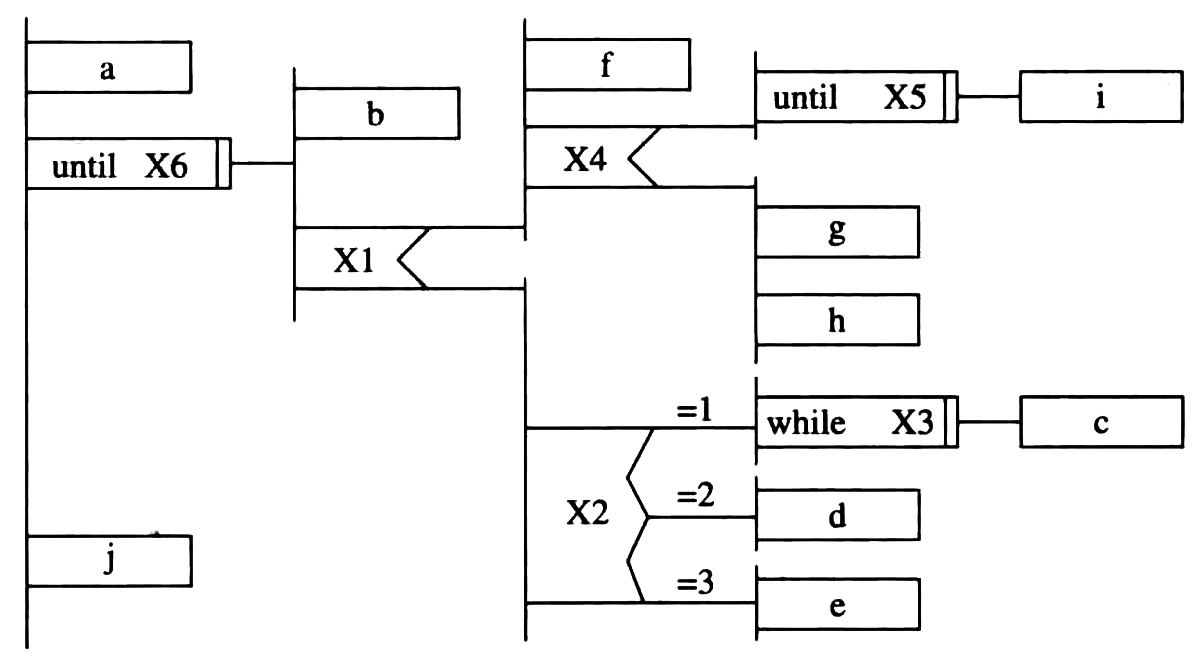
Figure 54: PAD实例
- PAD的优点
- 使用PAD符号所设计出来的程序必然是 结构化 程序。
- PAD描绘程序 结构清晰 ,图中竖线的总条数就是程序的层次数。
- 用PAD表现程序逻辑 易读 、 易懂 、 易记 。
- 容易将PAD 自动 转换为高级语言程序。
- PAD既可以表示 程序逻辑 ,也可用于描绘 数据结构 。
- PAD的符号支持 自顶向下 、 逐步求精 方法的使用。
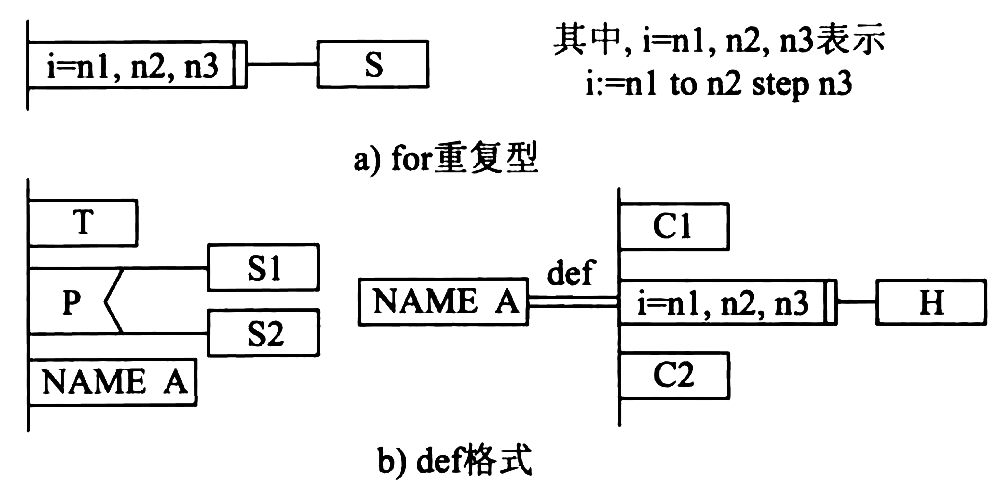
Figure 55: PAD的扩充控制结构
6.5. PDL与伪代码
- 程序设计语言(Program Design Language, PDL)
是一种 设计 和 描述 软件 方法 与 过程 的手段。
- 它与伪代码有关,但与伪代码不同的是,它采用 简单语言 编写,且不暗示使用任何编程语言或库的术语。\(^*\)
- \(^*\) https://en.wikipedia.org/wiki/Program_Design_Language
- 伪代码(Pseudocode) 是一种介于 自然语言 和 形式化语言 之间的
半形式化语言 , 是一种描述 功能模块 的 算法设计 和 加工细节 的语言。\(^{**}\)- \(^{**}\) https://en.wikipedia.org/wiki/Pseudocode
- 伪代码的语法规则:
- 外语法(outer syntax) 应当 符合 一般程序设计语言常用语句的 语法规则 ;
- 内语法(inter syntax) 可以用英语中一些简单的 句子 、 短语 和通用的 数学符号 来 描述 程序应执行的 功能 。
- 伪代码实例(以商店业务处理系统中检查订货单为例)
IF 客户订货金额超过5000元 THEN
IF 客户拖延未还赊欠钱款超过60天 THEN
在偿还欠款前不予批准
ELSE (拖延未还赊欠钱款不超过60天)
发批准书、发货单
ENDIF
ELSE (客户订货金额未超过5000元)
IF 客户拖延未还赊欠钱款超过60天 THEN
发批准书、发货单,并发催款通知书
ELSE (拖延未还赊欠钱款不超过60天)
发批准书、发货单
ENDIF
ENDIF
- 伪代码的基本控制结构
- 简单陈述句结构 :避免复合语句。
- 判定结构 :
if-then-else或case-of结构。 - 重复结构 :
while-do或repeat-util结构。
- 伪代码的特点
- 有固定的关键字外语法 ,提供全部结构化 控制结构 、 数据说明 和
模块特征 。 外语法的关键字是有限的词汇集,它们能对伪代码正文进行结构分割,使之变得易于理解。 - 内语法使用自然语言来描述处理特性 ,为开发者提供方便,提高
可读性 。 - 有数据说明机制 ,包括简单的(如标量和数组)与复杂的(如链表和层次结构)的 数据结构 。
- 有子程序定义与调用机制 ,用以表达各种方式的 接口说明 。
- 有固定的关键字外语法 ,提供全部结构化 控制结构 、 数据说明 和
- 你更愿意或倾向使用哪种工具?为什么?
| 参与人数 | 0 |
|---|---|
| 程序流程图 | 0 |
| N-S图 | 0 |
| PAD | 0 |
| PDL或伪代码 | 0 |
6.6. 自顶向下、逐步细化的设计过程
- 自顶向下、逐步细化的设计过程包括的两个方面
- 概要设计阶段 逐步细化
- 将复杂问题的 解法 分解细化 成由若干模块组成的 层次结构 ;
- 详细设计阶段 编码阶段 逐步求精
- 将每个模块的 功能 逐步 分解细化 为一系列具体的 处理 和
步骤 , 进而 翻译 成一系列用某种程序设计语言写成的 程序 。
- 将每个模块的 功能 逐步 分解细化 为一系列具体的 处理 和
- 概要设计阶段 逐步细化
- 在处理较大的 复杂任务 时,常采取 模块化 的方法,即
- 在程序设计时不是将全部内容放在同一模块中, 而是分成若干 模块 ,每个模块实现一个功能。
- 模块分解完成后,下一步的任务就是将每个模块的功能逐步分解细化为一系列的 处理 。
- 自顶向下、逐步细化的实例
要求用筛选法求 \(100\) 以内的素数。 所谓的筛选法,就是从 \(2\) 到 \(100\) 中去掉 \(2, 3, 5, 7\) 的倍数, 剩下的就是 \(100\) 以内的素数。
为了解决这个问题,可以按程序功能写出以下框架:
main() {
建立2到100的数组A[],其中A[i]=i; #1
建立2到10的素数表B[],存放2到10以内的素数; #2
若A[i]=i是B[]中任一数的倍数,则剔除A[i]; #3
输出A[]中所有没有被剔除的数; #4
}
- 将框架中的每个加工语句进一步细化成循环语句
main() {
// 建立2到100的数组A[],其中A[i]=i #1
for (i = 2; i <= 100; i++) A[i] = i;
// 建立2到10的素数表B[],存放2到10以内的素数 #2
B[1] = 2; B[2] = 3; B[3] = 5; B[4] = 7;
// 若A[i]=i是B[]中任一数的倍数,则剔除A[i] #3
for (j = 1; j <= 4; j++)
检查A[]所有的数能否被B[j]整除并将能被整除的数从A[]中剔除 #3.1
// 输出A[]中所有没有被剔除的数 #4
for (i = 2; i <= 100; i++)
若A[i]没有被剔除,则输出之 #4.1
}
- 对语句
#3.1和语句#4.1的细化
(直到最后每个语句都能直接用程序设计语言来表示为止)
main() {
// 建立2到100的数组A[],其中A[i]=i #1
for (i = 2; i <= 100; i++) A[i] = i;
// 建立2到10的素数表B[],存放2到10以内的素数 #2
B[1] = 2; B[2] = 3; B[3] = 5; B[4] = 7;
// 若A[i]=i是B[]中任一数的倍数,则剔除A[i] #3
for (j = 1; j <= 4; j++)
// 检查A[]所有的数能否被B[j]整除并将能被整除的数从A[]中剔除 #3.1
for (i = 2; i <= 100; i++)
if (A[i] / B[j] * B[j] == A[i])
A[i] = 0;
// 输出A[]中所有没有被剔除的数 #4
for (i = 2; i <= 100; i++)
// 若A[i]没有被剔除,则输出之 #4.1
if (A[i] != 0)
printf("A[%d] = %d\n", i, A[i]);
}
- 完善为编码阶段可编译运行的C语言程序
#include <stdio.h>
void main() {
// 建立2到100的数组A[],其中A[i]=i #1
int A[101], B[5];
for (int i = 2; i <= 100; i++) A[i] = i;
// 建立2到10的素数表B[],存放2到10以内的素数 #2
B[1] = 2; B[2] = 3; B[3] = 5; B[4] = 7;
// 若A[i]=i是B[]中任一数的倍数,则剔除A[i] #3
for (int j = 1; j <= 4; j++)
// 检查A[]所有的数能否被B[j]整除并将能被整除的数从A[]中剔除 #3.1
for (int i = 2; i <= 100; i++)
if (A[i] / B[j] * B[j] == A[i])
A[i] = 0;
// 输出A[]中所有没有被剔除的数 #4
// 向A[]中补充10以内的素数 #4.1
A[2] = 2; A[3] = 3; A[5] = 5; A[7] = 7;
for (int i = 2; i <= 100; i++)
// 若A[i]没有被剔除,则输出之 #4.2
if (A[i] != 0)
printf("%d ", A[i]);
}
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97
- 自顶向下、逐步求精方法的优点
- 自顶向下、逐步求精方法 符合 人们解决复杂问题的普遍 规律 。 可 提高 软件开发的 成功率 和 生产率 。
- 用 先全局后局部 、 先整体后细节 、 先抽象后具体 的逐步求精的过程
开发出来的程序具有 清晰的层次结构 ,因此程序 容易 阅读 和
理解 。 - 程序自顶向下、逐步细化,分解成树形结构。 在同一层的结点上做细化工作,相互之间没有关系,因此它们之间的细化工作相互 独立 。 在任何一步发生错误,一般只影响它下层的结点,同一层其他结点不受影响。
- 程序 清晰 和 模块化 ,使得在修改和重新设计一个软件时, 可复用 的代码量最大。
- 程序的逻辑结构 清晰 ,有利于程序 正确性 证明。
- 每一步工作仅在上层结点的基础上做不多的设计扩展, 便于检查 。
- 有利于设计的 分工 和 组织 工作。
7. 软件设计规格说明
- GB/T 8567-2006 《计算机软件文档编制规范》中有关软件设计的文档有3种,即:
- 《软件设计说明(SDD)》
- 《数据库设计说明(DBDD)》
- 《接口设计说明(IDD)》
这几个文档 互相补充 ,向用户提供了可视的 设计方案 , 并 为软件开发和维护提供了所需的信息 。
7.1. 软件(结构)设计说明(SDD)
- 软件设计说明 描述了软件系统的设计方案,包括:
- 系统级的设计决策
- 体系结构设计(概要设计)
- 实现该软件系统所需的详细设计
参考教材
- 4.7 pp.108-109
7.2. 数据库(顶层)设计说明(DBDD)
- 数据库设计说明 描述了:
- 数据库设计
- 存取与操纵数据库的软件系统
参考教材
- 4.7 p.109
7.3. 接口设计说明(IDD)
- 接口设计说明 描述了:
- 系统
- 硬件
- 软件
- 人工操作
- 其他系统部件的接口特性
接口设计说明(IDD) 与 接口需求规格说明(IRS) 配合,用于沟通和控制接口的设计决策。
参考教材
- 4.7 p.110
8. 软件设计评审
所有模块的设计文档完成以后,就可以对 软件设计 进行 评审 :
- 软件需求 是否得到满足:
- 确认该设计是否 覆盖 了所有已确定的软件 需求 ;
- 软件设计成果的每一成分是否可追踪到某一项需求,即 满足 需求的 可追踪性 。
- 软件结构 是否达到要求:
- 质量
- 接口 说明
- 数据结构 说明
- 实现 和 测试 的 可行性
- 可维护性
- ……
8.1. 概要设计评审的检查内容
概要设计评审的检查内容如下:
| 1. 系统概述 | 6. 属性设计 | 11. 清晰性 |
| 2. 系统描述和可追踪性 | 7. 数据结构 | 12. 一致性 |
| 3. 是否对需求分析中不完整、易变动、潜在的需求进行了相应的设计分析 | 8. 运行设计 | 13. 可行性 |
| 4. 总体设计 | 9. 出错处理 | 14. 详细程度 |
| 5. 接口设计 | 10. 运行环境 | 15. 可维护性 |
参考教材
- 4.8.1 pp.110-111
8.2. 详细设计评审的检查内容
详细设计评审的检查内容如下:
| 1. 清晰性 | 6. 数据 | 11. 性能 |
| 2. 完整性 | 7. 功能性 | 12. 可靠性 |
| 3. 规范性 | 8. 接口 | 13. 可测试性 |
| 4. 一致性 | 9. 详细程度 | 14. 可追踪性 |
| 5. 正确性 | 10. 可维护性 |
参考教材
- 4.8.2 pp.111-112
9. 课后作业
- 习题4.5 使用数据流图和处理叙述,描述一个具有明显事物流特性的计算机系统。 使用本章所介绍的技术定义数据流的边界,并将DFD映射成软件结构。
- 习题4.7 用面向数据流的方法设计第3章习题3.6所描述的图书管理系统的软件结构, 并尽量使用改进方法对模块结构进行精化。
- 习题4.9 将大的软件划分成模块有什么好处?是不是模块化分得越小越好? 划分模块的依据是什么?
- 习题4.10 什么叫 自顶向下、逐步细化 ?